Abstract
- Weakly-supervised Spatio-Temporal Video Grounding(WS-STVG) task는 기존의 STVG task와 비슷하나, densely annotated training data 없이 수행하는 방법을 의미한다.
- VTP(Video-Text Prompting)을 제안하여 candidate feature를 생선한다. 이는 tube를 만들기 위해서 video prompt를 red circle과 같은 visual marker로 추가하는 형태이다.
- candidate feature끼리 비슷하게 보이는 경우에는 constrastive VTP(CVTP)를 제안하여 해결했다.
Motivation
weakly supervised STVG는 heavily annotated data가 필요 없다는 점에 강점이 있다. WS-STVG는 video clip과 corresponding query만 주어지고 bounding box나 temporal annoation은 제공되지 않는다는 특징이 있다.
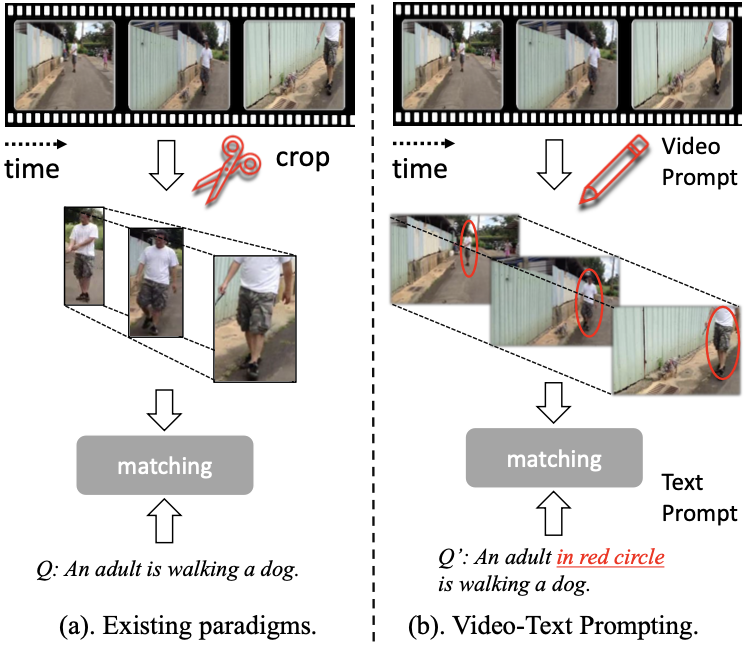
기존의 WS-STVG task를 푸는 방법들은 주로 two-stage로 진행하면서, detector가 먼저 만들어낸 entity tube를 grounding하는 형태로 문제를 풀었다. 그러나 이 방법은 moving trajectory나 entity의 global context를 반영하지 못한다는 문제가 있음을 지적한다(Fig. 1 (a) 참조).

따라서 여기에서는 tube를 잘라내서 사용하는 것이 아니라 video prompt로 만들고 이를 활용하는 방식을 제안한다(Fig. 1 (b) 참조). 그리고 query sentence를 변형하여 in red circle 등의 지칭어를 포함한다.
다만 이 경우에 생성된 candidate instance들이 incorrect candidate일 수 있다. 이건 꽤 복잡한 문제라서, 이를 해결하기 위해 Constrastive VTP(CVTP)를 제안한다.

CVTP는 강조된 object를 erase함으로써 생성하는 형태인데, 만약 해당하는 object가 올바른 object라면 CVP counterpart의 matching score이 줄어들 것으로 생각할 수 있다. 반면 강조된 object가 별 관련이 없는 object라면 둘의 차이는 크지 않을 것이다.
이 intuition을 기반으로 올바른 VTP candidate를 찾는다(Fig. 2 참조).
Methods
Experiments
Results
Discussion
References
Footnotes
'DL·ML > Paper' 카테고리의 다른 글
| VideoLISA (NeurIPS 2024,VOS) (0) | 2025.01.02 |
|---|---|
| MoRA (arXiv preprint, STVG) (0) | 2025.01.02 |
| CG-STVG(CVPR 2024) (1) | 2024.12.31 |
| Conditional MixLoRA (ACL 2024, MLLM PEFT) (0) | 2024.10.02 |
| Video-LaVIT (ICML 2024 Oral, Video tokenization) (0) | 2024.09.30 |