STVG Task
STVG(spatio-temporal video grounding) task는 text query에 맞는 spatiotemporal 영역을 video 안에서 grounding하는 task이다.

이때 구성되는 sequence of bounding boxes를 spatio-temporal tube라고 한다.
text query는 Fig. 1과 같이 declarative할 수도 있고, interrogative할 수도 있다.

그전까지의 방법은 Fig. 2 (a)와 같이 video와 query를 보고 object를 retreive하는 방식이었다. 그러나 일반적으로 textual query는 object를 retrieve하는 데에 충분하지 않다. 따라서 text query를 길게 할 수도 있으나 여기에도 여러 가지 제약 조건이 따른다.
따라서 visual information을 보조 정보로 활용하고자 하는 것이 이 paper의 주요 contribution인데, 당연하게도 task 정의 상 text 말고는 사용할 수 없으니 video를 통해서 visual context information을 추출하여 supplementary guidance로 사용한다.
여기에는 ICG(Instance Context Generation) module과 ICR(Instance Context Refinement) module이 사용된다. ICG는 object의 visual information을 추출하는 데에 사용되는데, region을 추출하여 appearance와 motion information을 얻는다.
여기에 포함된 noise를 제거하기 위해서 ICR이 사용된다. temporal and spatio relevance score를 사용하여 irrelevant feature를 suppress하고 localization을 개선한다. 이를 위해 DETR-like architecture를 사용한다.
Methods

CG-STVG는 encoder-decoder architecture를 따른다.
Multimodal Encoder
먼저 $N_v$개의 frame을 sample하여 $\mathcal{F} = \{f_i\}^{N_v}_{i=1}$ frame set을 얻는다. 이를 ResNet-101을 이용하여 appearance feature extraction, VidSwin으로 motion feature extraction을 한다.
appearance feature $\mathcal{V}_a = \{v^a_i\}^{N_v}_{i=1}$ $\text{where } v^a_i \in ℝ^{H×W×C_a}$와 motion feature $\mathcal{V}_m = \{v^m_i\}^{N_v}_{i=1}$ $\text{where } v^m_i \in ℝ^{H×W×C_m}$을 얻는다.
text feature는 RoBERTa로 먼저 query를 tokenize하여 $\mathcal{W} =\{w_i\}^{i=N_t}_{i=1}$를 얻은 다음 RoBERTa로 embedding sequence $\mathcal {T} = \{t_i \}^{i=N_t}_{i=1}$ where $t_i \in ℝ^{C_t}$를 얻는다.
얻은 feature들은 fusion하는데, linear projection으로 channel dimension을 동일하게 맞춰준 다음 concatenate하여 multimodal feature $\mathcal {X} = \{x_i\}^{N_v}_{i=1}$를 얻는다.

여기에 positional embedding $\mathcal {E}_{pos}$ 와 $\mathcal{E}_{typ}$를 더한 뒤 self-attention encoder를 거쳐 최종적인 multimodal feature $\tilde {\mathcal{X}}$를 얻는다 :
$$ \tilde {\mathcal {X}} =SAEncoder(\mathcal {X} + \mathcal {E}_{pos} + \mathcal{E}_{typ})$$
Context-Guided Decoder for Grounding
Fig. 3 (a)를 보면 각 stage마다 spatial-decoding block(SDB)와 temporal-decoding block(TDB)가 있는 것을 볼 수 있다. $\mathcal{Q}$를 spatial query feature, $\mathcal{P}$를 temporal query feature라고 했을 때 SDB를 이용하여 query feature $\mathcal{Q}_k$를 learn하게 된다.
SDB와 TDB는 구조가 약간 다른데(Fig. 3 (b) 참조), SDB는 2개의 cross-attention과 1개의 self-attention으로 구성된다:

TDB는 마지막이 MLP로 구성된다는 점이 다르다:

Instance Context Generation(ICG)
ICG는 SDB를 통해 얻은 spatial query feature $\mathcal{Q}$를 받아 foreground feature를 얻는 것이다. intuition은 progressive하게 video grounding을 할 때 $\mathcal{Q}$가 positional information을 점점 더 많이 포함하여 video 안에서 target region을 찾는 데에 이용될 수 있다는 것이다.
따라서 MLP를 이용하여 feature $\mathcal{Q}$를 foreground region $\mathcal{R}$로 바꾼다:

이때 $r^k_i\in ℝ^4$는 objectcenter and scale in frame $i$를 의미한다.
이는 RoIAlign을 통해 원래 위치를 찾는 데에 사용될 수 있다:

Instance Context Refinement(ICR)

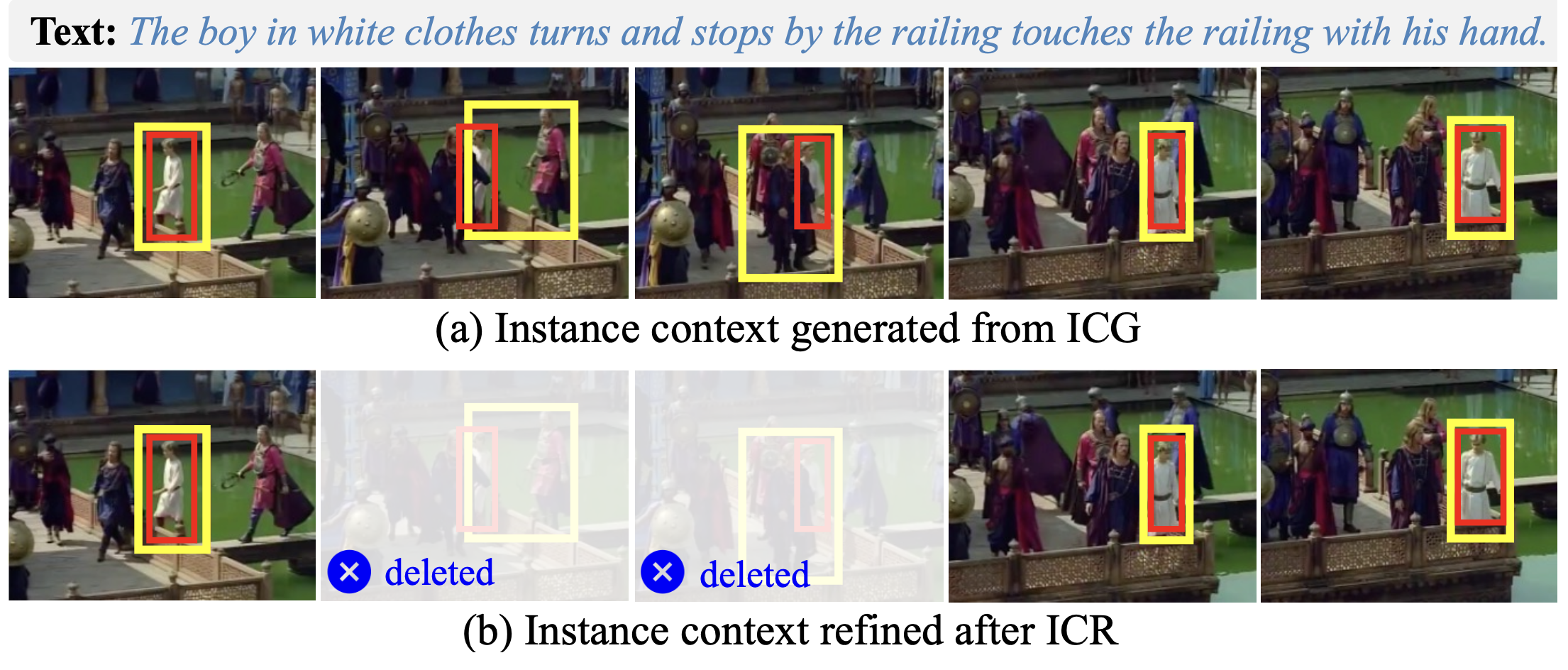
ICR을 하는 이유는, 종종 ICG에서 얻는 region들이 context와 무관하거나 harmful할 수 있기 때문이다. 이를 위해 temporal query feature $\mathcal{P}$를 leverage해서 temporal confidence score를 얻는다:

confidence score가 높을수록 isntance feature의 relevancy가 높은 것으로 이해한다. 만약 confidence score가 threshold보다 낮으면 drop한다:

여기서 θ는 threshold, HF는 high-pass filter를 의미한다.
즉 여기서는 spatial한 것은 보지 않고, temporal하게만 검수해서 몇 개의 frame을 drop하는 것이다.
이와 비슷하게 다만, spatial feature에 대해서도 filtering을 적용한다.
적용 후의 결과는 Fig. 5와 같다:
Experiments
dataset은 HCSTVG-v1, HCSTVG-v2, Vid-STG, HCSTVG를 사용했다.
Results
Discussion
* text encoder가 약하니까 당연히 reasoning하는 것까지는 안 될 것 같다. LLM이 필요할 것 같은데
* 왜 그냥 drop했을까? refine할 때 더 좋은 방식이 많을 것 같은데
→ refine한다음에 GT랑 비교해서 그 부분을 train하면 더 좋은 거 아닌가?
References
[1] Zhang, Zhu, et al. "Where does it exist: Spatio-temporal video grounding for multi-form sentences." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020.
Footnotes
'DL·ML > Paper' 카테고리의 다른 글
| MoRA (arXiv preprint, STVG) (0) | 2025.01.02 |
|---|---|
| VTP(EMNLP 2024, STVG) (0) | 2025.01.01 |
| Conditional MixLoRA (ACL 2024, MLLM PEFT) (0) | 2024.10.02 |
| Video-LaVIT (ICML 2024 Oral, Video tokenization) (0) | 2024.09.30 |
| UniHOI (NeurIPS 2023) (0) | 2024.09.24 |