![[DL] Vision Transformer (ViT)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbNpXJw%2FbtsrjpTAe89%2FBtkG3DBVxW7myg5mKRv9B0%2Fimg.png)
https://arxiv.org/abs/2010.11929
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
While the Transformer architecture has become the de-facto standard for natural language processing tasks, its applications to computer vision remain limited. In vision, attention is either applied in conjunction with convolutional networks, or used to rep
arxiv.org
Abstract
이 논문이 나온 21년도 전까지는 transformer achitecture는 NLP task에서만 주로 사용되었다. 이 논문의 contribution은 CNN 위주로 사용하던 vision task에 pure transformer architecture를 적용해서 image classification task에서 SOTA를 달성해 가능성을 보였음에 있다.
Introduction
Transformer는 2017년에 처음 제안되었는데, computational efficiency와 큰 parameter에도 saturate하지 않는 scability 때문에 널리 사용되었다. 그러나 vision task에서는 Tranformer를 적용하려는 시도가 성공적이지 못했다.
이 논문에서는 기본 Transformer architecture를 최대한 보존하면서 image 도메인에 적용한다. 이를 위해서 image를 patch로 자르고 Transformer의 input으로 이 patch들의 linear embedding sequence를 넣는다. Image patch들은 token처럼 사용된다.
ViT는 ImageNet 같은 작은 크기의 데이터셋에서는 ResNet보다 낮은 성능을 보였고, 14M 이상의 큰 데이터셋의 경우에는 좋은 성능을 보였다. 이는 Transformer가 spatial structure를 사용하는 CNN과 달리 inductive bias가 없기 때문에 적은 양의 데이터에는 충분히 generalize하지 못하기 때문이라고 해석한다.
Architecture

Sequencify
architecture는 위와 같다. 먼저 image를 고정된 크기의 patch로 자른 뒤 flatten한다. 위 그림을 보면, 전체 이미지가 $x\in \mathbb R^{H\times W\times C}$일 때, 이를 작은 크기의 2d patch로 먼저 자른다. 그럼 $x_{patch} \in \mathbb R ^{P\times P\times C}$를 $N = HW/P^2$개 얻게 된다.
이 patch들은 tokenize해야 한다. 여기서는 단순히 patch를 1d vector로 flatten해서 사용한다. 그럼 patch vector의 각 크기는 $P^2 C$이므로 전체 patch seqeunce의 크기는 $x_p \in \mathbb R ^{N \times (P^2 C)}$가 된다.
그 후 linear layer를 거쳐 $D$ dimenstion으로 projection한다. 즉 $E \in \mathbb R^{(P^2C) \times D}$를 곱해준다.
Class token & Positional embedding
위의 과정으로 얻은 embedded patches의 맨 앞에 token을 하나 붙여준다. $[class]$ token인데, 이는 learnable한 parameter로 BERT에서와 유사한 기능을 한다.
또한 Positional embedding은 $E_{pos} \in \mathbb R^{(N+1)\times D} $ 형태로 patch embedding에 더해진다. 즉 이를 표현하면 다음과 같다.
$$ z_0 = \left [ x_{class} ; x_p^1 E; x_p^2 E; \cdots ; x_p^N E;\right] + E_{pos} $$
Multiheaded self-attention & MLP
그 다음은 기존 Transformer encoder와 유사하게 multiheaded self-attention과 MLP layer를 거친다.

이를 수식으로 표현하면 다음과 같다.
$$ z'_l = MSA(LN(z_{l-1}))+z_{l-1}$$
$$ z_l = MLP(LN(z'_l)) + z'_l$$
$$ y = LN(z^0_L)$$
수식을 보면 multiheaded self-attention을 거치기 전 layer norm을 한 번 거치고, 그 다음 residual connection으로 더해줘서 $z'_l$을 얻는다. 그 다음 이를 LN을 한 번 더 거친 후 MLP와 residual connection으로 값을 얻어 $z_l$을 계산한다. 최종적인 값은 마지막에 LN을 거친 후 $y$를 얻는다.
Analysis
Inductive bias
논문에서 재미있는 분석을 하나 하는데, CNN에 비해 Transformer architecture가 가진 inductive bias가 훨씬 약하다는 점에 주목한다. CNN은 locality나 translation equivalence 같은 inductive bias를 가지고 있다. locality는 2d neighborhood를 반영하는 것을 의미하고, translation equivalence는 input의 위치에 따라 output이 달라지지 않는 것을 의미한다.
반면 self-attention layer는 global하게 계산되고, 2d locality는 patch를 자를 때에만 반영된다. 이 지점을 이후 작은 크기의 데이터에서 ViT가 기존의 CNN 기반 SOTA 모델에 비해 낮은 성능을 보인 이유로 분석한다.
Hybrid architecture
patch를 1d vector로 바꾸는 embedding을 linear projection으로 하지 않고, CNN의 feature map을 사용할 수도 있다. 이 형태를 hybrid model이라고 이름 붙이고 실험을 통해 비교한다.
Fine-tuning and Higher resolution
ViT는 큰 데이터셋에서 pretrain되고, downstream task에 fine-tuning 되었다. task를 바꾸기 위해서 pre-trained prediction head를 제거하고 $K$개의 class를 가진 downstream task에 맞는 $D\times K$ prediction head를 붙여 사용했다.
이전 연구에서 higher resolution으로 fine-tuning 하는 것이 더 좋다고 알려져 있으므로 그러한 방법을 따랐는데, 이 경우 patch의 개수가 달라진다는 문제가 있다. 이러면 pretrained position embedding을 사용할 수 없기 때문이다. 따라서 기존의 position embedding을 2d interpolation하여 사용했다.
Results
결과는 ResNet과 ViT와 hybird를 가지고 비교했다.
Datasets
다음 데이터셋을 사용했다.
- ImageNet (1k classes, 1.3M images)
- ImageNet-21k (21k classes, 14M images)
- JFT (18k classes, 303M images)
Model variants

위와 같은 configuration의 ViT variants를 사용했다.
Image classification results
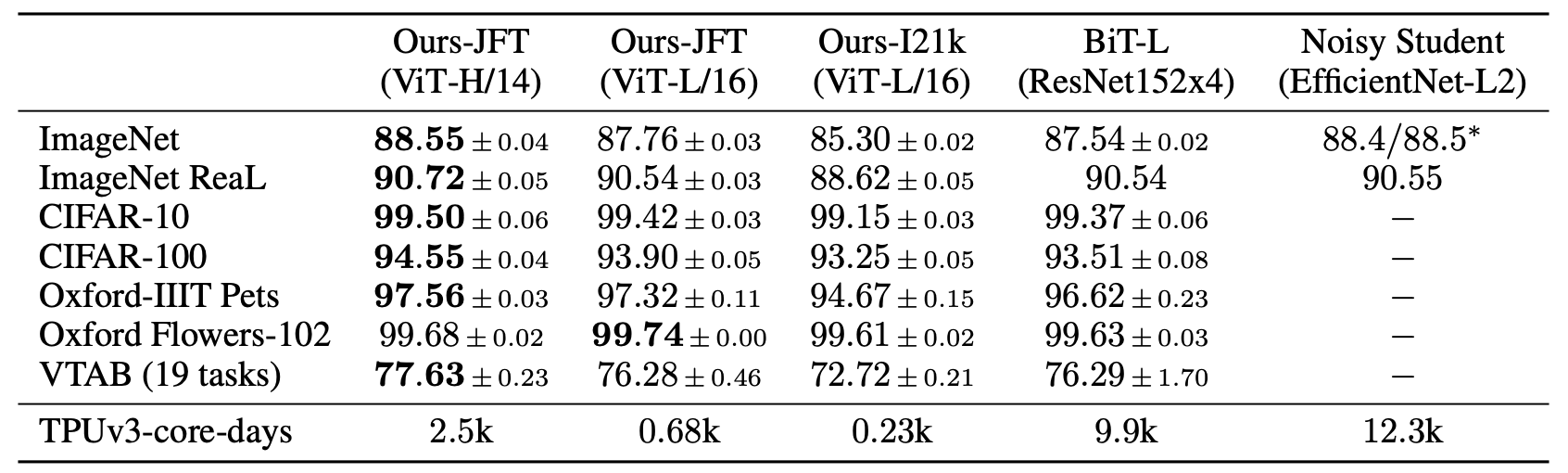
ViT-H/N 은 patch size가 $N\times N$임을 의미한다. Table 2는 classifciation task에서의 결과를 보여준다. 21k에서 학습시킨 경우 SOTA에 비해 떨어지지만, JFT에 pretrained 모델은 모든 dataset에서 ResNet을 outperform함을 볼 수 있다.
이외에도 VTAB performance에서도 SOTA 성능을 보인다.
Data requirements
dataset의 크기가 얼마나 중요한지 알아보기 위한 실험을 진행했다.
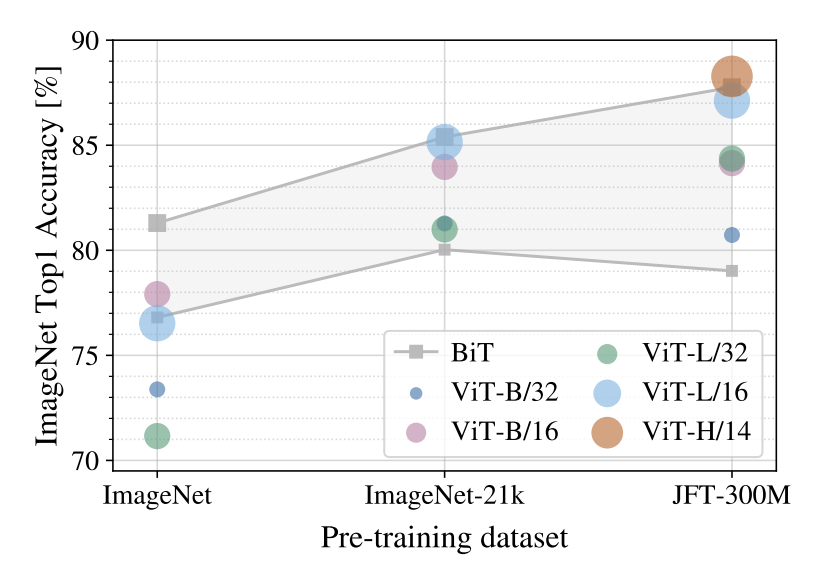
Figure 3는 각 크기의 dataset에서 모델을 pretrain한 후 ImageNet에 fine-tuning 했을 때의 accuracy를 보인다. 작은 크기의 데이터셋에서는 기존 모델에 비해 성능이 떨어지고, ViT가 큰 모델일 수록 성능은 더 떨어진다. 데이터셋의 크기가 커졌을 때 큰 모델이 좋은 성능을 낸다.
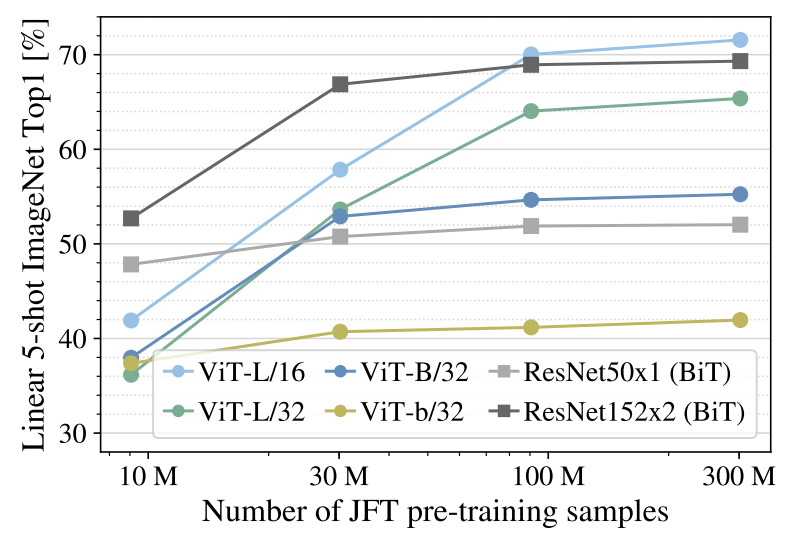
Figure 4는 few shot setting에서 ImageNet 성능을 보여준다. 가로축은 JFT에서 각 개수의 random subset으로 pretraining시킨 것을 의미한다. 9M subset에서는 ViT 성능이 크게 떨어지지만, 90M 이상의 subset에서는 ResNet보다 좋은 성능을 보인다.
References
[1] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., ... & Polosukhin, I. (2017). Attention is all you need. Advances in neural information processing systems, 30.
[2] Pulfer, B. (2023, February 21). Vision Transformers from Scratch (PyTorch): A step-by-step guide. Medium. https://medium.com/mlearning-ai/vision-transformers-from-scratch-pytorch-a-step-by-step-guide-96c3313c2e0c
Footnotes
'DL·ML' 카테고리의 다른 글
| [GNN] Visual genome dataset (0) | 2023.09.15 |
|---|---|
| [GNN] GCN을 이용한 Image Captioning 구현 (0) | 2023.08.24 |
| [GNN] GCN을 이용한 Image Captioning (0) | 2023.08.14 |
| [GNN] MixHop architecture (0) | 2023.07.17 |
| [GAN] Minibatch Discrimination (0) | 2023.01.21 |