https://arxiv.org/abs/1809.07041
Exploring Visual Relationship for Image Captioning
It is always well believed that modeling relationships between objects would be helpful for representing and eventually describing an image. Nevertheless, there has not been evidence in support of the idea on image description generation. In this paper, we
arxiv.org
Abstract
GCN과 LSTM을 결합한 architecture를 이용하여 semantic and spatial object relationship을 image encoder에 반영한다.
Introduction
CNN이나 RNN 기반 image encoding 방법은 image 안의 object 간 relationship을 반영하지 못한다는 한계가 있다. 이 paper에서는 어떻게 image 내의 object 간 inherent relationship을 반영하여 holistical한 방식으로 image를 해석할 수있는지에 대해 다룬다.
여기서 다루는 connection은 semantic connection과 spatial connection으로 나눌 수 있다. 각 graph는 detected region을 vertex로 하고 relationship을 edge로 한 directed graph로 구성된다. GCN은 그 이후 graph representation을 enrich하기 위해 사용된다.

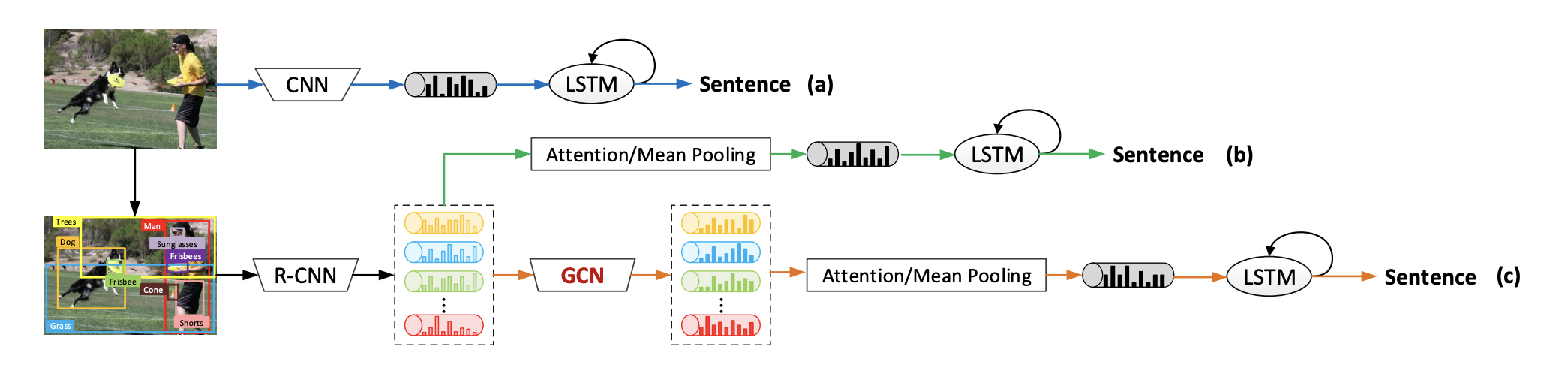
전체적인 flow는 아래 줄과 같다. 이미지에서 R-CNN을 통해 region proposal을 받고, region으로 graph를 만든다. GCN을 돌린 후 attention LSTM decoder로 sentence를 만든다.
Image Captioning by Exploring Visual Relationship
위에서 설명한 아키텍처를 그림으로 나타내면 Figure 2와 같다. R-CNN으로 image region을 얻어서, 두 종류의 그래프로 encoding하고, LSTM attention mechanism으로 decode한다.
또한 sentence generation problem의 loss는 다음과 같은데,
=> 추가 설명 필요
Semantic Object Relationship
여기서는 일반적인 semantic relation이
Figure 3은 semantic relation detection framework를 보여준다. 보면 붉은색 region과 초록색 region이
그럼 이미지에
Spatial Object Relationship
Spatial object relationship은 두 region 간 관계를 object j의 object i에 대한 관계
파란색 bounding box가 j이고 붉은색이 i이다. class 1, 2, 3은 special case이다. 세 class에 해당하지 않을 경우 relative distance/diagonal length ratio
이 graph는 every object에 대해 edge를 만든다. 그리고 각각 edge에 대해 위의 관계에 따라 class label이 붙는다.
GCN based Image Encoder
original GCN은 undirected graph에서 동작한다.
여기에 directed graph의 방향에 따라 사용하는 weight가 다르고, edge의 label에 따라서 사용하는 bias가 달라야 하므로
형태로 사용한다.
여기에 추가로 edge-wise gate unit
로 사용한다.
Q1. 그럼 vertex(object)의 feature는 뭘로 정의하냐?
Q2. edge의 클래스는 어디에서 반영한다는거냐?
-> (vi, vj)의 레이블에 따라 다른 bias 값을 더해준다. 근데? 어차피 bias값은 랜덤 아닌가?
Attention LSTM Sentence Decoder
LSTM decoder는 위와 같이 구성된다.
- Attention LSTM decoder collects word, previous state,
image feature and concats them :
- Normalized attention distribution over all the relation-
aware region-level feature is generated as :
- Second-layer LSTM unit is calculated as :
References
Footnotes
'DL·ML' 카테고리의 다른 글
| [GNN] GCN을 이용한 Image Captioning 구현 (0) | 2023.08.24 |
|---|---|
| [DL] Vision Transformer (ViT) (0) | 2023.08.17 |
| [GNN] MixHop architecture (1) | 2023.07.17 |
| [GAN] Minibatch Discrimination (0) | 2023.01.21 |
| [GAN] mode collapse (0) | 2023.01.10 |