
Motivation
pose estimation만을 수행하는 vision model들은 comprehensive한 이해가 결여되어 있다. 여기서는 LLM의 prior knowledge를 활용하여 3D human pose를 SMPL 형태로 generation하도록 한다. 이를 위해 LLM이 기존에 갖고 있는 3D pose에 대한 이해를 확인하고 추가적으로 어떻게 teach할 수 있는지 확인한다.
Methods
Architecture
text 또는 visual input을 받을 수 있다. 이를 이용해 textual output 또는 SMPL pose를 출력한다.
모델은 LLM model
text string

Training
vision encoder와 vision projection은 freeze하고 SMPL pose projection layer
즉 pose lose는 L1 difference로 측정되고 λ term들은 weighting parameter들이다.
Text to Pose Generation
다음 template을 사용했다:
USER: {description}, can you give the SMPL pose of this person. ASSISTANT: Sure, it is <POSE>.
이를 통해 text에서 3D human pose를 generate했다.
Human Pose Estimation
3D human pose estimation는 일반적으로 cropped image으로 SMPL pose parameter를 regress한다. 여기서도 pair of cropped image와 SMPL pose parameter를 사용한다.
USER: <IMAGE> Can you provide the SMPL pose of the person in the center of
this image? ASSISTANT: Sure, the SMPL pose of this person is <POSE>.
여기서 Image는 image input token으로 replace된다. 이외에도 몇 가지 다른 QA pair도 사용하였으니 필요하다면 appendix를 참조하면 된다.
Multi-Modal Instruction Following
LLaVA-V1.5-MIX665K datset으로 instruction tuning하여 multi-turn conversation이 가능하도록 했다.
Reasoning about Human Pose
fine-tune된 이후에 model은 multi-turn dialogue을 진행하며 human pose reasoning에 대한 zero-shot capability를 보여주었다. 이 성능을 보이기 위해 두 task를 제안하는데 Speculative Pose Generation과 Reasoning-based Pose Estimation이다.
Speculative Pose Generation (SPG)
USER: {descriptions implicit}, can you give the SMPL pose of this person? ASSISTANT: Sure, it is <POSE>.
여기서는 explicit하게 pose를 descript하지 않고, implicit한 pose description에서 LLM이 추론하도록 한다. 예컨대,
"This man is proposing marriage, what pose might he be in?"
와 같은 질문은 marriage에서 pose를 reasoning할 수 있어야 한다. 이를 evaluation하기 위해 PoseScript dataset을 활용했다. 그 후 GPT4를 이용해서 desciption을 queestion으로 바꿔 20k response로 구성된 데이터셋을 구축하였다.
Reasoning-based Pose Estimation (RPE)
person 별로 box를 crop해서 pose estimation할 경우 주변 context가 반영이 안 된다는 문제가 있다.
USER:<IMAGE> {description person}, can you give the SMPL pose of this person? ASSISTANT: Sure, it is <POSE>.
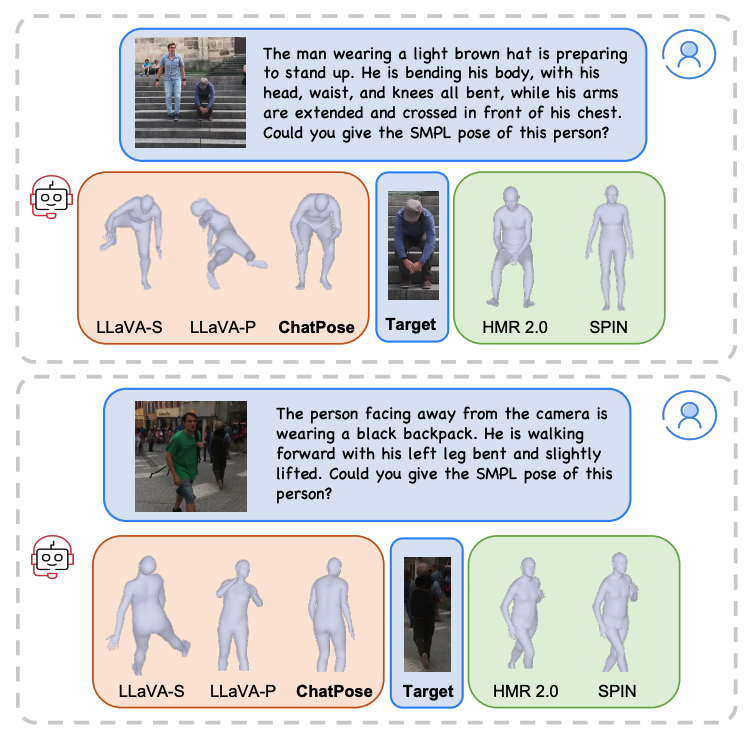
따라서 RPE에서는 user가 image에 대해서 질문을 먼저 한 후 person pose에 대해 질문한다. 정확히는 위와 같다. 여기서의 desciption person은 "The man with black hair" 또는 "the woman near the stair"로 scene context를 확인하도록 요구한다.
50 multiperson image를 3DPW test set에서 sampling하여 사용했다. 각 individual에 대해서 behavior, outfits, pose, shape, summary를 describe하도록 했고, 전체 250 q-a pair를 만들어서 evaluation에 활용했다.
Results
LLaVA-1.5V-13B를 LLM backbone으로 사용하고, CLIP과 Vicuna-13B를 사용하였다. vision encoder와 projection layer는 freeze하고 SMPL projection layer는 scratch로 training하고 LLM은 LoRA로 finetune하였다.
Datasets
text-to-SMPL pose pair는 PoseScript에서 얻었다.

Discussion
- MLLM은 pose task를 풀 수 있고, 그를 language와 연결할 수 있음
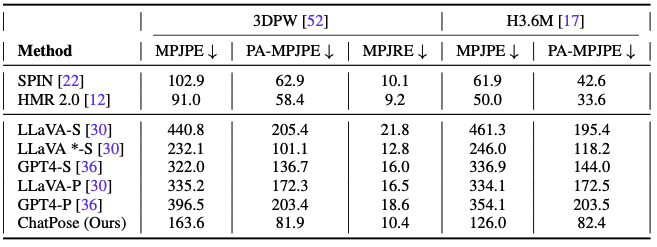
- 성능은 specialized regressor보다 떨어짐. → vision encoder freeze하면 안 됨.
- multiperson action에 대해서 prior 가질 수 있는지 확인해야
References
Footnotes
'DL·ML > Paper' 카테고리의 다른 글
| VPD (CVPR 2024 Oral, VLM) (0) | 2024.08.05 |
|---|---|
| InternVideo2 (VFM) (1) | 2024.07.25 |
| OMG-LLaVA (1) | 2024.07.16 |
| LLaVA-1.5 (CVPR 2024) (0) | 2024.07.12 |
| LLaVA (NeurIPS 2023 Oral, MLLM) (0) | 2024.07.10 |