Motivation

LLaVA에서 충분히 explore되지 않았던 부분을 다룬다. LMM(Large Multimodal Models)를 general-purpose assistant로 만들기 위해 가장 좋은 training design choice가 무엇인지 확인한다.
먼저 LLaVA의 vision-language connector는 linear projection으로 사용되었는데, 이것이 좋은 성능을 보임을 증명하고 개선한다. 그 후 LMM의 open problem에 대해서 explore하는데 이는 구체적으로 다음과 같다:
1) Scaling to high-resolution image inputs; high-resolution image로 scaling하는 것은 image를 diving into grid 하면 된다.
2) Compositional capbilities; LMM은 긴 형태의 language reasoning 등의 compositional capability를 가진다.
3) Data efficiency; 데이터의 양을 줄여도 성능이 significant하게 떨어지지 않는다.
4) Data scaling; data의 granularity와 model capacity를 동시에 높이는 것이 중요함을 보인다.
이를 이용하여 public data로 train한 LLaVA-1.5를 제안하고 많은 task에서 SOTA 성능임을 보인다.
Methods
Response Format Prompting
LLaVA가 짧은 답변을 요구하는 adademic benchmark에서 주로 fail하고, yes/no question에서 training data의 inbalance로 인해 yes를 답하는 경향이 있다는 점이다. InstructBLIP은 이런 문제를 해결했지만, 반대로 긴 답변을 요구하는 real-life visual conversation task에서 fail하는 경향이 있다. (See Tab. 1a)

이는 prompt 자체에서 response format을 지정하지 않아서 발생하는 문제로 보고 VQA 질문의 마지막에 output format을 명시한다. 이렇게 LLM을 finetune할 경우 사용자의 의도에 맞게 답변하게 된다. (See Tab. 1)

실제로 VQAv2를 포함하면 LLaMA의 MME performace가 비약적으로 향상된다. (See Tab. 2)
Scaling the Data and Model
- MLP vision-language connector
원래 쓰던 linear projection 대신에 layer를 하나 더 붙여서 two-layer MLP를 쓴다. 이게 LLaVA의 multimodal capability를 생성한다.
- Academic task oriented data
academic-task-oriented VAQ dataset을 추가했다.
- Additional Scaling
vision encoder를 CLIP-ViT-L-336px로 바꿔서 input image resolution을 $336^2$로 키웠다. 여기에 GQA dataset을 추가해 vision data를 늘리고, ShareGPT data까지 사용하였다. 마지막으로 LLM을 13B로 늘려서 최종적인 LLaVa-1.5 모델을 구성했다.
Scaling to Higher Resolutions
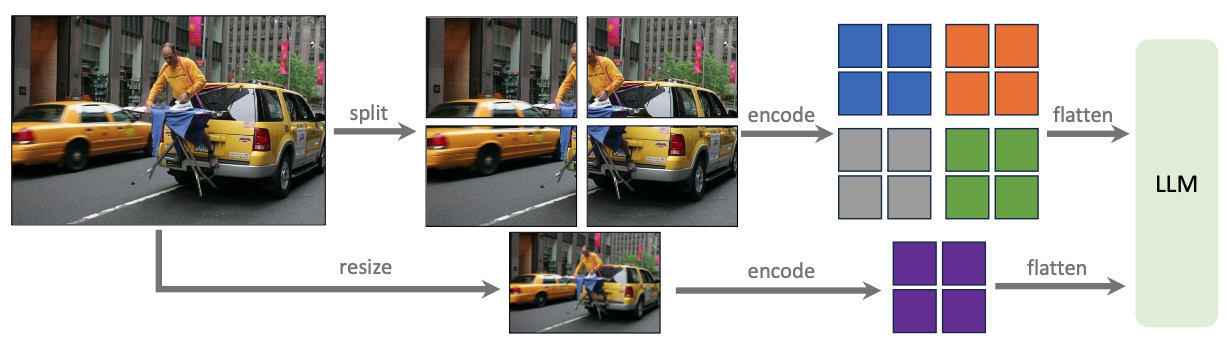
higher resolution image를 다루기 위해 기존 방법들은 positional embedding interpolation을 수행하고 ViT backbone을 finetune해야 했다. 이보다 efficient하게 하기 위해서 image를 smaller patch로 쪼개고 independent하게 encode한 뒤 combine해서 LLM에 feed했다. 여기에 global contect를 주기 위해서 downsampled image의 feature도 concatenate해서 사용했다. 이 모델은 LLaVA-1.5-HD로 명명되었다.
Discussion
References
[1] Liu, H., Li, C., Li, Y., & Lee, Y. J. (2024). Improved baselines with visual instruction tuning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 26296-26306).
Footnotes
'DL·ML > Paper' 카테고리의 다른 글
| ChatPose (CVPR 2024) (0) | 2024.07.17 |
|---|---|
| OMG-LLaVA (1) | 2024.07.16 |
| LLaVA (NeurIPS 2023 Oral, MLLM) (0) | 2024.07.10 |
| UniControl (NeurIPS 2023, Diffusion) (1) | 2024.07.08 |
| X-VARS (CVPR 2024) (0) | 2024.06.26 |