Motivation
LLaVA는 image-level analysis를 진행하므로 precise location과 같은 pixel-level에서의 작업을 수행할 수 없다는 문제가 있다. 여기에 extra detection model을 붙여서 문제를 해결하는 경우가 있지만, 이 경우 LLaVA가 image cpationing이나 VQA와 같은 image-level analysis의 성능을 잃게 된다는 문제가 있다.
OMG-LLaVA에서는 하나의 LLM과 visual encoder, decoder를 가지고 image-level, object-level, pixel-level task를 모두 수행하고자 한다. 특히 OMG-Seg model을 universal perception model로 사용한다. OMG-Seg의 encoder와 decoder를 freeze하여 pixel-level segmenation ability를 보존하고, LLM을 이용하여 referring segmentation이나 grounded conversation, generation task를 수행한다. 또한 image-level understanding 능력도 forget하지 않았음을 보인다.
Methods
Task Unification
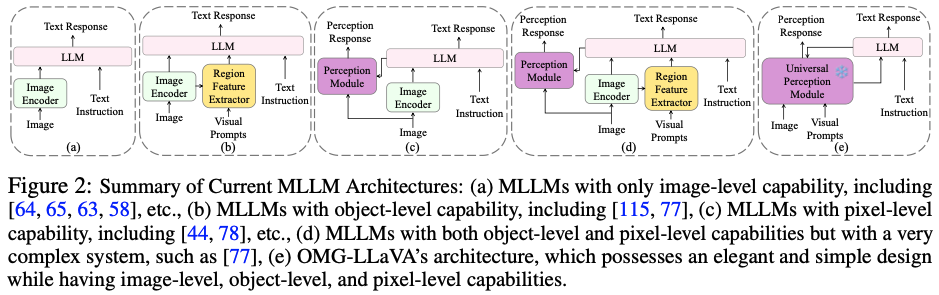
기존의 방법들은 여러 task를 처리하기 위해 복잡한 structure를 가지게 되었다. 반면 OMG-LLaVA는 Fig. 2 (e)와 같이 간단한 structure를 유지하면서 여러 task를 처리한다.
Unified View of DIfferent Tasks
여기서는 세 종류의 token을 정의하여 사용한다. text token $T_t$, pixel-centric visual token $T_{pv}$, object-centric visual token $T_{ov}$이다. pixel-centric visual token은 dense image feature를 represent하여 comprehensive image information을 feed한다. object-centric visual token은 specified object의 feature를 encode해서 object-centric information을 LLM에 제공하는 역할을 한다.
task는 다음과 같이 unify된다:
$$ T^{out}_t, T^{out}_{ov} = LLM(T^{in}_{pv}, T^{in}_{ov}, T^{in}_t)$$
일반적인 기존 task에 활용되는 text response $T_t^{out}$과 pixel-level reasoning task에서 사용되는 object-centric visual token $T^{out}_{ov}$가 generate된다.
pixel-centric visual token은 CLIP backbone 등으로 쉽게 얻을 수 있으나 object-centric visual token은 segmentation mask로의 decoding을 상정한다는 requirement가 있다. 따라서 OMG-Seg decoder를 사용해서 이 requirement를 충족한다.
OMG-LLaVA Framework

위에서 언급한 바와 같이 vision encoder와 decoder로 OMG-Seg를 쓰는데 여기서는 이를 universal perception module이라고 한다. 전체 구조는 freeze하고 사용한다.
Image Encoder
ConvNeXT-L-based CLIP을 image encoder로 사용하고 image resolution은 1024×1024로 사용한다. 이때 32× downsampling을 하여 크기를 줄인 후 pixel shuffle operation를 추가로 사용하여 resolution을 더 줄여 256개의 64 dim visual token이 만들어지도록 한다.
OMG Decoder

Fig. 4 (left)에서 볼 수 있듯이 OMG decoder는 image feature와 prompt query에 대해서 cross attention과 self-attention을 수행한다.
prompt로는 point, box와 mask를 받을 수 있다. box를 단순히 point로 바꾸면 정보 손실이 극심하므로 masked cross-attention layer에 constraint를 부과한다. Fig. 4 (right)와 같이 box는 box 외부의 pixel에 대해서 attention mask를 정의한다. 또한 mask가 주어진 경우에는 그냥 그대로 사용한다.
Perception Prior Embedding

당연히 freeze한 perception module을 그냥 LLM에 붙이면 올바르게 동작하지 않는다. 따라서 perception prior embedding strategy를 제안하는데, 이는 Fig. 5에 illustrate되어 있다.
OMG decoder를 통해 얻은 object query로 segmentation mask $\mathcal {M} \in ℝ^{N_q×HW}$와 confidence score $\mathcal {S}∈ℝ^{1×N_q}$를 predict한다. 이를 이용해서 mask score $MS \in ℝ^{HW×N_q}$를 각 pixel에 대해서 계산한다.
$$ MS= Softmax (\mathcal {M} ⊙ \mathcal {S} , dim=-1)$$
이를 다시 object query와 weighted average를 하고 image feature $\mathcal {F}$를 더해 pixel-centric visual token을 만든다.
$$T_{pv} = MS \cdot \mathcal{Q} + \mathcal {F}$$
이렇게 만들어진 ov token과 pv token은 concatenate되어 $T_v = (T_{pv}, T_{ov})$로 LLM에 input으로 사용된다.
Visual Projector and Text Projector
MLP를 visual projector로 사용한다. token이 두 종류라서 동일한 MLP를 쓸 수는 없고, 두 MLP를 사용한다.
Instruction Formulation
visual input과 text input, visual prompt를 받는다. special token은 세 개가 있는데, <Image>, <Region>, [SEG]이다. <image> token은 visual token으로 replace된 두 LLM에 feed되고, <Region>는 ov token으로 replace된다. [SEG] token은 LLM의 output에 있는 것으로 OMG decoder가 segmentation mask로 decode 하도록 한다.
Experiments
Results
Discussion
References
Footnotes
'DL·ML > Paper' 카테고리의 다른 글
| InternVideo2 (VFM) (1) | 2024.07.25 |
|---|---|
| ChatPose (CVPR 2024) (0) | 2024.07.17 |
| LLaVA-1.5 (CVPR 2024) (0) | 2024.07.12 |
| LLaVA (NeurIPS 2023 Oral, MLLM) (0) | 2024.07.10 |
| UniControl (NeurIPS 2023, Diffusion) (1) | 2024.07.08 |