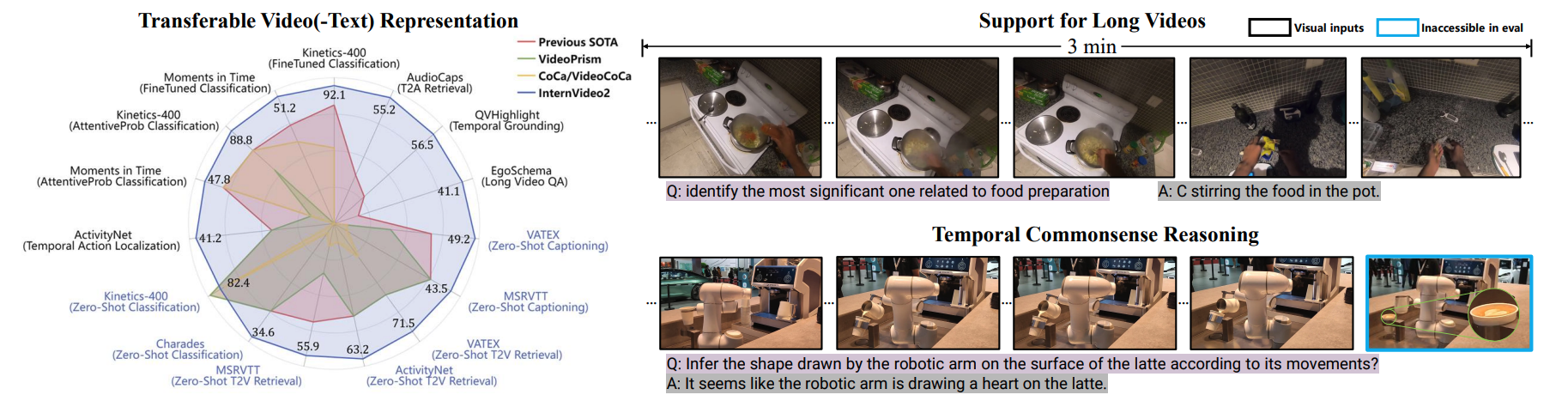
Motivation

InternVideo2는 three stages of learning scheme으로 spatiotemporal perception을 개선한다. 처음에는 VideoMAE처럼 maksed video token prediction을 수행한다. 두 번째 stage로 multimodal learning을 수행하여 audio와 text에 대해서도 task를 수행할 수 있게 된다. 마지막으로 InternVideo2를 LLM에 붙여 next-token prediction training함으로써 contextually appropriate token을 generate하도록 train된다.
Method
video encoder로 CLIP을 쓰지 않고 ViT를 쓴다. 여기에 attention pooling과 distillation을 위한 projection layer를 붙여서 사용한다.
video에 대해서는 8 frame을 sampling한 뒤 14×14 spatial downsampling을 진행한다. 이 token들은 class token과 함께 spatiotemporal하게 concatenate되어서 3D pos embedding이 더해진다. hyperparamater setting은 InternViT-6B와 같다
Stage 1: Reconstructing Masked Video Tokens
특이하게 teacher를 하나 쓰는 게 아니라 여러 개 사용한다. InterVL과 motion-aware model VideoMAEv2를 이용해서 semantic guidance를 받는다. 이를 이용해서 다음 objective를 minimize한다:
이 방식으로 multimodal에 friendly하고 action recognition 능력을 향상시켰다고 주장한다.
Stage 2: Aligning Video to Audio-Speech-Text
audio, text, speech를 align해서 InternVideo2에 활용하였다. audio encoder로는 12-layer Transformer initialized with BEATs를 사용하여 64d audio spectogram에서 feature를 extract했다.
pretraining objective는 crossmodal contrastive and matching losses with masked language reconstruction으로 다음과 같다:
CON 이외의 MAC, MLM loss는 [2]를 참조하면 된다.
video
MLM loss는 autoregressive하게 next token prediction을 수행한다.
Aligning Masked Visual-Language-Audio
audio encoder freeze하고 먼저 visual, text feature를 aligning한다. dataset은 image, video, audio-video 데이터를 가지고 pretrain했다.
VAS는 video, audio, speech의 concatenated feature를 의미한다.
Unmasked Visual-Audio-Language Post-Pretraining
masking하지 않고 video를 freeze한 상태에서 align을 강화했다.
Stage 3: Predicting Next Token with Video-Centric Inputs
video encoder의 embedding을 enrich하고 user-friendly하게 만들기 위해서 video BLIP과 incorporate했다. training 과정은 VideoChat2를 따랐다.
References
[1] Jiang, B., Chen, X., Liu, W., Yu, J., Yu, G., & Chen, T. (2024). Motiongpt: Human motion as a foreign language. Advances in Neural Information Processing Systems, 36.
[2] Feng Cheng, Xizi Wang, Jie Lei, David J. Crandall, Mohit Bansal, and Gedas Bertasius. Vindlu: A recipe for effective video-and-language pretraining. ArXiv, abs/2212.05051, 2022.
Footnotes
'DL·ML > Paper' 카테고리의 다른 글
| VoT (ICML oral, video understanding) (0) | 2024.08.06 |
|---|---|
| VPD (CVPR 2024 Oral, VLM) (0) | 2024.08.05 |
| ChatPose (CVPR 2024) (0) | 2024.07.17 |
| OMG-LLaVA (1) | 2024.07.16 |
| LLaVA-1.5 (CVPR 2024) (0) | 2024.07.12 |