Motivation
- Multimodal instruction-following data 제작: 처음으로 vision-language domain에 instruction tuning 활용
- Large multimodal model: CLIP에 Vicuna 붙여서 finetuning함.
- Multimodal instruction-following benchamrk: LLaVA-Bench
Dataset

image-text pair 데이터는 있어도, instruction-following multimodal dataset은 만들기가 expensive해서 그 양이 많지 않다. 여기서는 ChatGPT/GPT-4를 이용해서 data를 collect했다.
기존의 image-text pair를 가지고, $\text{Human: (question) (image) <STOP> Assistant: (caption) <STOP>}$ 형태로 만드는 것은 쉽지만 깊이 있는 reasoning과 divesity가 lack되어 있는 단점이 있다.
따라서 visual content에 따른 instruction-follwing data를 만들기 위해 ChatGPT/GPT-4를 사용한다. 다만 여기서는 text-only GPT를 활용하기 때문에 image를 활용하지는 않고, Tab. 1과 같이 image의 caption과 bbox를 text prompt로 넣어준다. 처음에는 몇 개의 example을 manual하게 만들었고, 이를 in-context learning에 활용하였다.
구체적인 prompt는 다음과 같다:
- Conversation: model이 image를 보는 것처럼 conversation하는 형태
- Detailed description: rich and comprehensive description of an image
- Complex reasoning: in-depth reasoning questions
Visual Instruction Tuning
Architecture
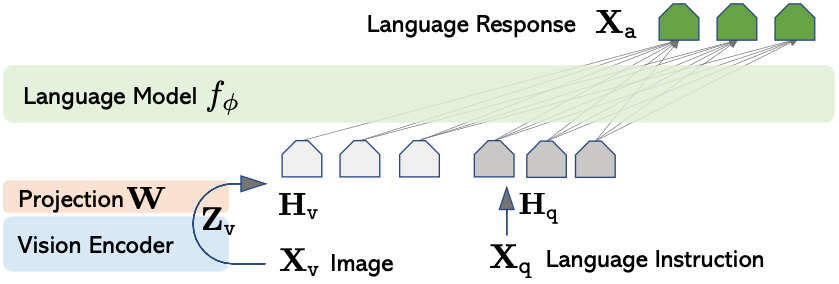
전체 architecture에서는 어떻게 image를 LLM과 함께 align하여 사용할 수 있을지 생각해야 한다. 여기서는 language model로 Vicuna를 사용하고, vision encoder로는 CLIP ViT-L/14를 사용한다. image $X_v$를 vision encode $g$r로 encode해서 visual feature $Z_v$를 얻은 후 linear projection matrix $W$를 사용하여 LLM의 word embedding space에 align된 visual token을 얻는 간단한 방식이다.
$$ H_v = W\cdot Z_v, \text{ with } Z_v=g(X_v)$$
물론 linear projection layer보다 cross attention 등이 aligning에 더 좋은 결과를 낸다고 알려져 있는 것은 자명하나 여기서는 간단하게 진행하였다.
Training

train에는 multi-turn conversation data $(X^1_q, X^1_a, \cdots, X^T_q, X^T_a)$를 활용했다. 이때 $T$는 the number of turns이다. 그리고 각 turn의 instruction $X^t_{instruct}$는 다음과 같이 설정되었다:
$$\begin{equation}
\mathbf{X}_{\text{instruct}}^t =
\begin{cases}
\text{Randomly choose } [\mathbf{X}_q^1, \mathbf{X}_v] \text{ or } [\mathbf{X}_v, \mathbf{X}_q^1], & \text{the first turn } t = 1 \\
\mathbf{X}_q^t, & \text{the remaining turns } t > 1
\end{cases}
\end{equation}
$$
복잡할 것은 없고, 그냥 첫 turn에만 image를 주는데 question과 image의 순서가 바뀔 수 있고, 나머지는 question만 주는 것이다. 이렇게 되었을 경우 Fig. 2와 같은 형태의 전체 instruction이 만들어진다. 이는 수식으로는 다음과 같이 표현된다:
\begin{equation}
p(\mathbf{X}_a \mid \mathbf{X}_v, \mathbf{X}_{\text{instruct}}) = \prod_{i=1}^L p_{\theta}(x_i \mid \mathbf{X}_v, \mathbf{X}_{\text{instruct}}, <i, \mathbf{X}_a, <i)
\end{equation}
system-message와 <STOP> token은 readability를 위해 빠졌는데, 식의 의미는 visual data를 aware하면서 autoregressive하게 만들어지는 것을 믜한다.
LLaVA training은 two-stage instruction tunign procedure로 이루어진다:
- Stage 1: Pre-training for Feature Alignment
CC3M을 filtering해서 595K image-text pair로 만들어 train한다. visiual encoder와 LLM은 둘 다 freeze하고, projection만 train해서 align하도록 한다. 즉, stage 1은 linear projection layer를 frozen LLM에 align하는 과정이다.
- Stage 2: Fine-tuning End-to-End
visual encoder는 그대로 freeze하고 LLM과 linear projection layer를 fine-tuning한다. training에서는 multimodal chatbot을 상정하여 multi-turn conversation을 포함했다. Response type은 conversation, detailed description, complex reasoning인데, 이 중 conversation만 multi-turn이다. 자세한 것은 Tab 1+.를 참조하면 좋다.

Experiments


Quantitative한 평가를 위해서 text-only GPT-4를 비교군과 judge로 사용했다. GPT-4에 같은 질문을 textual description과 함께 넣어주고 GPT-4와 LLaVA의 결과를 GPT-4 judge가 평가하도록 했다. 이는 1에서 10 사이의 숫자로 helpfulness, relevance, accuracy, level of detail of the response가 평가되었다. 이는 Tab. 4에서 확인할 수 있다.


LLaVA-Bench는 두 종류로 만들었는데, COCO base로 만든 것과 In-the-Wild로 ㅁ난들었다.
COCO base bench는 COCO-Val-2014에서 randomly selected 30 images에 세 종류의 euqestion을 만들어서 90개의 question으로 구성한 것이다. 이 결과는 Tab. 5에서 확인할 수 있다.
In-the-Wild base bench는 다양한 source에서 collect된 24개의 image와 60개의 question이다. 이를 기존의 여러 multimodal model들과 비교한 것이 Table 6에서 나타난다. LLaVA-Bench In-the-Wild는 사진만 가지고는 판단하기가 어려운 복잡한 task로 구성되어 있으며 이는 Tab. 7에서 확인할 수 있다.

Discussion
- Tab. 7에서 오른쪽 column의 question 2에서 LLaVA의 대답은 "yes"인데, 실제 냉장고에는 strawberry와 yogurt는 있지만 strawberry-flavored yogurt는 없다. 이는 LLaVA가 visual data를 "bag of patches"로 인식하고, image의 complex semantic을 포착하는데 실패했음을 의미한다.
- visual data 뿐 아니라 pose data나 bbox 등에도 align 시킬 수 있어야 다른 복잡한 task에 활용할 수 있을 듯
- 그렇게 했을 때 그냥 text prompt로 주는 것보다 잘 할까? → QFormer?
- CLIP encoder가 freeze되어 있으면 이미지의 미묘한 semantic은 포착하기가 어려울 듯. fine-tuning 없이 task-specific하게 할 수는 없을지?
References
[1] Liu, H., Li, C., Wu, Q., & Lee, Y. J. (2024). Visual instruction tuning. Advances in neural information processing systems, 36.
Footnotes
'DL·ML > Paper' 카테고리의 다른 글
| OMG-LLaVA (1) | 2024.07.16 |
|---|---|
| LLaVA-1.5 (CVPR 2024) (0) | 2024.07.12 |
| UniControl (NeurIPS 2023, Diffusion) (1) | 2024.07.08 |
| X-VARS (CVPR 2024) (0) | 2024.06.26 |
| BASNet (CVPR 2019, OD) (0) | 2024.06.14 |