
Abstract

- HyperSeg는 image, video scenario 모두에서 동작하는 VLM-based universal segmentation model이다.
- HyperSeg에서는 hybrid entity recognition module과 fine-grained visual perceiver module을 사용한다.
Motivation
기존 MLLM-based segmentation 방법론들은 한정된 domain 내에서만 동작한다는 limitation이 있다.
HyperSeg에서는 text prompt와 visual prompt(box, mask, etc)를 모두 사용하는 task를 해결한다. 또한 여러 visual domain의 문제를 풀기 위해서 세 가지 방법론을 사용한다:
1. 기존 encode-only methods나 decode-only methods는 mask token을 generate하거나 decode하기만 한다는 점에 tackle해서; incorporate a hybrid entity recognition strategy → VLLM의 generative ability를 활용해서 mask token을 만들면서 동시에 decode한다.
2. CLIP encoder가 coarse-level visual feature를 사용한다는 점을 tackle해서; Fine-grained Visual Perceiver(FVP)를 사용해서 multi-scale visual feature를 fixed-length fine-grained token으로 사용한다.
3. 기존 method들의 temporal understanding이 약하다는 점을 tackle해서; temporal adapter를 새로 제안하여 사용한다.
Methods
Overview
VLLM input은 세 종류인데, 1) visual tokens, 2) fine-grained visual tokens, 3) prompt tokens이다. output은 mask tokens 또는 prompt tokens인데 이는 segmentation predictor에 feed되어 segmentation mask를 predict한다. 추가적으로 space-time information propagation과 global prompt aggregation을 활용한다.
Visual Large Language Model
LLM은 lightweight LLM을 쓰고, visual encoder도 CLIP과 같은 low-resolution encoder를 사용한다.
Eq. 1은 CLIP encoder가 visual input을 처리하고 LLM에 feed해서 output embedding
위의
OVS, VIS
RES, R-VOS, ReasonVOS
VOS
Segmentation Predictor
Segmentation predictor
mask는
Loss
Loss는 eq. 3, 4와 같이 define된다.
Hybrid Entity Recognition
Fig. 3을 보면, (a)는 seq generation으로 object를 찾는데, 이 경우 object를 miss하거나 repetitive objects를 generate하는 경우가 있다.
(b)는 VLLM을 mask를 class name decode하는 용도로 사용한다.
(c) VLLM은 vision input의 object들을 generate하도록 하고, mask도 생성한다. 바로 생성하는 것은 아니고 token 형태로 만들어 predictor가 generate한다.
→ 여기서의 decode라고 말하는 것은 prompt embedding을 활용하여 class prediction을 한다는 이야기인 듯. paslm하고 omg-llava 다시 보고 무슨 말인지 확인해봐야 할 듯.
근데 이게 뭔말이여 ?
Fine-grained Visual Perceiver
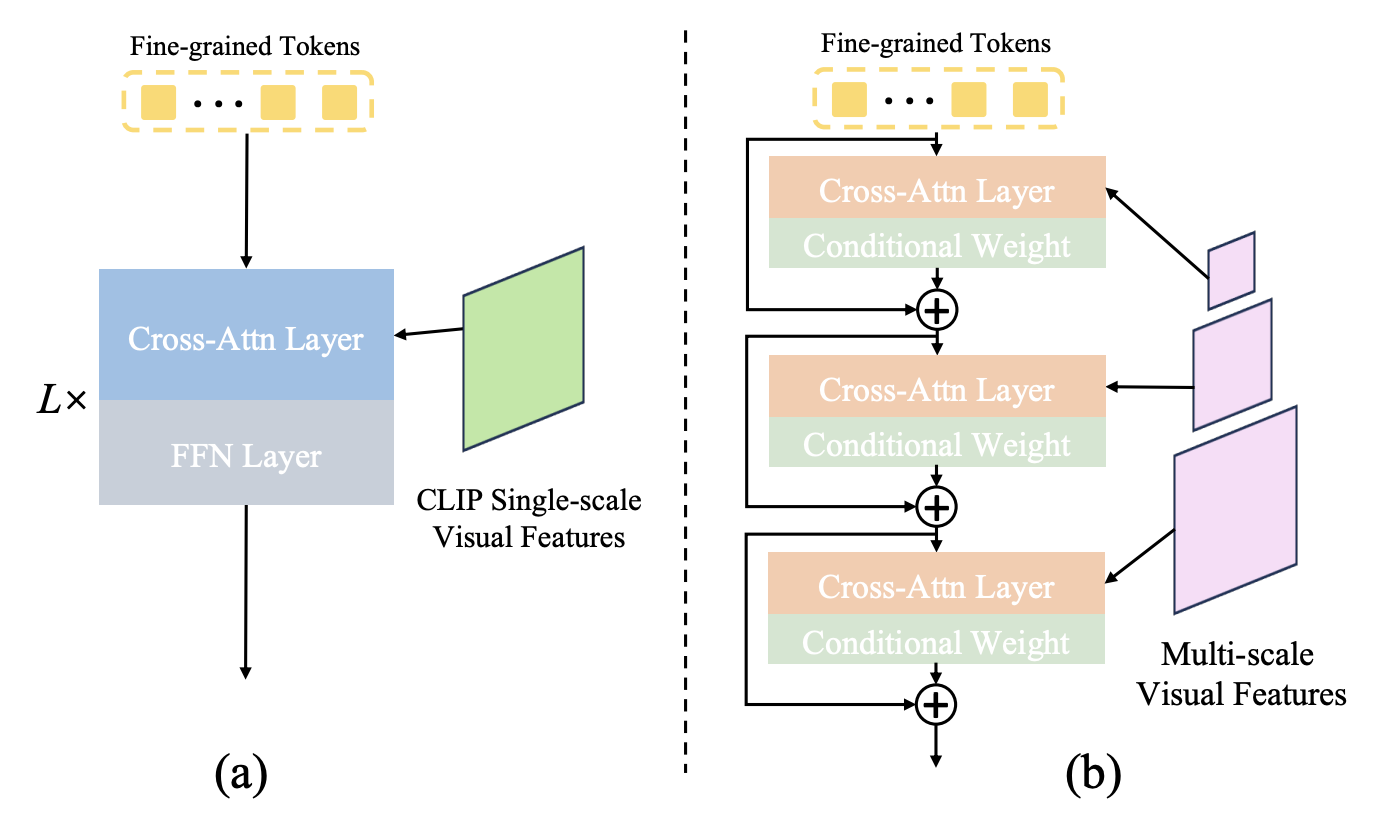
CLIP encoder만으로는 fine-grained feature를 얻을 수 없다고 생각해서 pyramid vision encoder를 사용한다. vision input
→ frame sampling 어떻게 하는거야?
Temporal Adapter
time-dimension을 aware하기 위해서 global prompt aggregation을 사용한다.
Global prompt aggregation
current prompt embedding
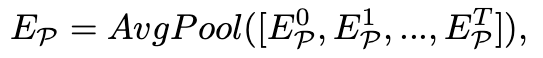
Local space-time information injection
previous feature의 정보를 포함하는 projection function
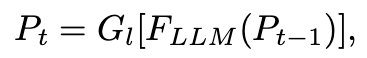
Experiments
Results
Discussion
* video encoding을 어떻게 했다는 건지 나와있지가 않다.
코드를 확인해 보니 모든 image를 independent하게 처리한다. https://github.com/congvvc/HyperSeg/blob/main/eval/eval_ReasonVOS.py
HyperSeg/eval/eval_ReasonVOS.py at main · congvvc/HyperSeg
Project for "HyperSeg: Towards Universal Visual Segmentation with Large Language Model". - congvvc/HyperSeg
github.com
line 120부터 참조
References
Footnotes
'DL·ML > Paper' 카테고리의 다른 글
| PSALM (ECCV 2024, Image Segmentation) (0) | 2025.01.10 |
|---|---|
| InstructSeg (arXiv preprint) (1) | 2025.01.07 |
| VISA (ECCV 2024, RVOS) (0) | 2025.01.03 |
| VideoLISA (NeurIPS 2024,VOS) (1) | 2025.01.02 |
| MoRA (arXiv preprint, STVG) (0) | 2025.01.02 |