https://arxiv.org/abs/2407.11325v1
VISA: Reasoning Video Object Segmentation via Large Language Models
Existing Video Object Segmentation (VOS) relies on explicit user instructions, such as categories, masks, or short phrases, restricting their ability to perform complex video segmentation requiring reasoning with world knowledge. In this paper, we introduc
arxiv.org
Abstract
- reasoning video object segmentation (ReasonVOS) 제안
→ 나와야 할 수순이기는 했다. 왜 아직까지도 없었는지? - VISA (Video-based large language Instructed Segmentation Assistant) 제안
→ ReasonVOS를 풀기 위한 MLLM 기반 segmentation 방법
Motivation
Reasoning Video Object Segmentation (ReasonVOS) task 제안; complex and implicit instruction in video로 binary mask sequence를 generate하는 것
이 문제 풀기 위해 VISA 제안; long term video feature를 encode하면서 spatial detail를 preserve할 수 있는 방법
→ Text-guided Frame Sampler(TFS)로 most relevant frame을 sample한다.
그리고 LISA와 같은 방식으로 <SEG> token을 사용하여 segmentation mask를 generate한다.


Methods
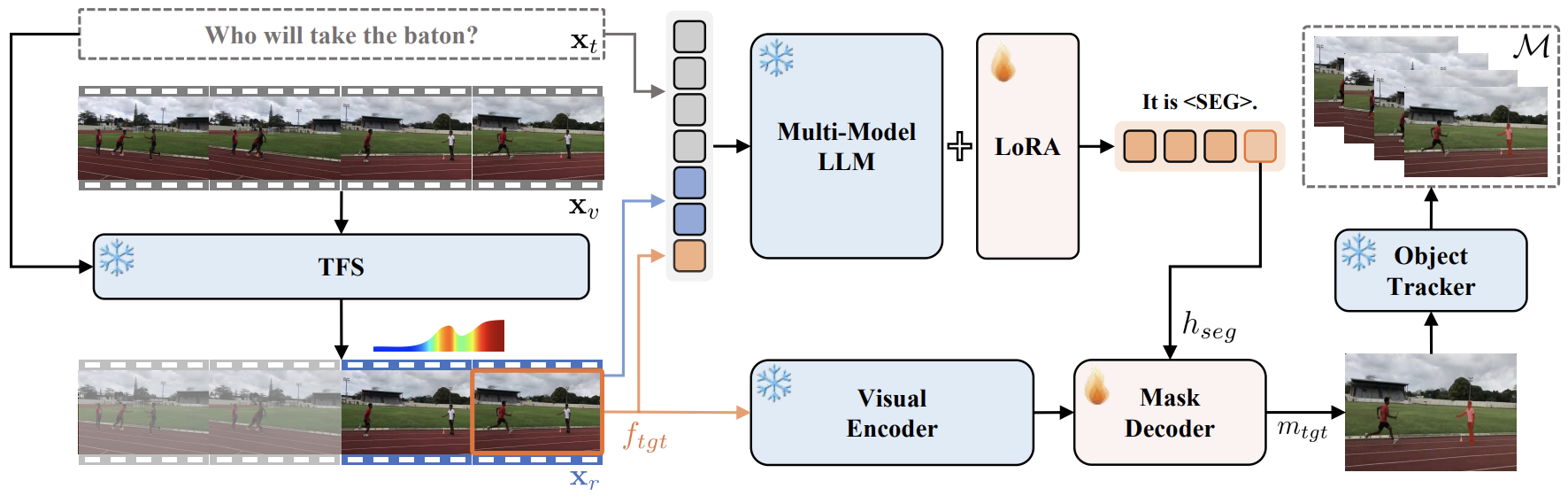
VISA는 3 components로 구성된다: Text-guided Frame Sampler(TFS), MLLM, Object Tracker.
먼저 input video는 TFS에 feed되어 target frame $f_{tgt}$와 long term information을 얻기 위한 $T_r$개의 corresponding reference frames $x_r$이다.
이 selected frame은 MLLM에 feed되고, target frame에 대한 segmentation special token <SEG>를 return한다.
이를 통해 Object Tracker가 bi-directional mask propagation을 통해서 모든 frame에 대해 segmentation mask를 generate한다.
→ 대충 형태가 SAM-2랑 비슷한듯
Text-guided Frame Sampler
각 frame 별로 $L$개의 token으로 represent하면, 전체 $T$개의 frame에 대해 $TL$개의 visual token이 generate되는데, 이는 너무 많은 양이라서 MLLM에 feed할 수 없다.
paper에서는 다만, Fig. 3의 "Which person will take the baton?"이라는 question에 대해서 마지막 몇 개의 frame만 봐도 답변할 수 있음을 지적한다.
따라서 LLaMA-VID를 사용해서 각 frame을 2개의 visual token으로 만들어 긴 video를 확인할 수 있게 한다. 그리고 most distinguishing frame $f_{tgt}$와 corresponding reference frames $x_r$를 만들어 MLLM에 feed할 수 있도록 한다. feed는 다음 template으로 수행된다:
"<VIDEO> To find {description}, which percentage mark of the video should I check? Please respond with a number between 0% and 100%."
여기서 top-K response에서 value를 추출해 10개의 평균을 내서 사용한다.
→ reference frame이 정확히 뭔지, LLaMA-VID를 어떻게 사용했다는 건지 잘 모르겠다. video를 다 안 보면 못 푸는 문제가 있을텐데. .
Multimodal Large Language Model
$x_r$ frame과 $f_{tgt}$는 ViT로 encode되고 Spatial Merging으로 $L$ visual embedding된다.
그 다음 text token과 concatenate해서 MLLM에 feed한다. feed에 사용되는 template은 다음과 같다:
"USER: $<f_{tgt}><x_r>$ Can you segment the {description}? ASSISTANT: Yes, it is <SEG>."
이렇게 얻은 <SEG> token의 last layer embedding을 linear projection을 거쳐 SAM decoder에서 prompt embedding으로 사용하였다.
ReVOS Dataset
implicit한 instruction을 만들기 위해서 LV-VIS, MOSE, OVIS, TAO, UVO에서 video를 모아서 complex text instruction으로 annotate하였다. 전체 1,042개의 video에 대해 35,074 object-instruction pair가 있다.
Experiments

Chat-UniVi-7B와 Chat-UniVi-13B를 MLLM으로, SAM을 segmentation decoder로 사용하였다. XMem을 object tracker로, TFS로는 LLaMA-VID를 사용했다. 이는 모두 freeze했고 LoRA로 finetune했다.



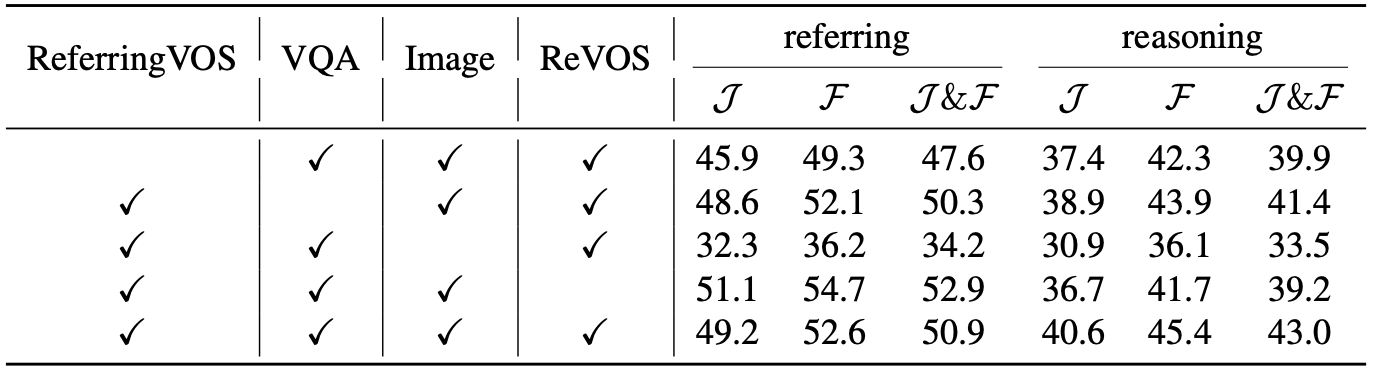



Discussion
paper에서 제시한 limitation은 다음과 같다:
1. very small object에 대한 capturing 능력이 떨어짐(Fig. 4 (d) 참조). → small paddles are not segmented
2. temporal information gathering; 정확한 frame을 찾는 데에 실패하면 결과가 좋지 않음
→ 방법이 별로다
여기서도 wiggly smoggy하게 mask가 generation되는 것이 mask decoder를 finetune해서 그런 거 같고.. 그냥 내 생각에는 prompt를 잘 주면 될 것 같은데
그리고 결국 video로 MLLM에 feed하니까 high-resolution image를 못 보는 거 아닌가?
high res img를 딱 중요한 거 하나 뽑아서 한 장 보면 안되는지? 그리고 거기에서 prompt만 잘 만들고 그걸로 SAM이 알아서 propagate하게
References
Footnotes
'DL·ML > Paper' 카테고리의 다른 글
| InstructSeg (arXiv preprint) (1) | 2025.01.07 |
|---|---|
| HyperSeg (arXiv preprint, seg) (0) | 2025.01.06 |
| VideoLISA (NeurIPS 2024,VOS) (1) | 2025.01.02 |
| MoRA (arXiv preprint, STVG) (0) | 2025.01.02 |
| VTP(EMNLP 2024, STVG) (0) | 2025.01.01 |