
Abstract
https://arxiv.org/abs/2412.14006

- image와 video domain의 referring task와 reasoning task를 합쳐 Instructed Visual Segmentation(IVS) task로 통합했다.
- 이를 해결할 수 있는 InstructSeg 모델을 제안한다.
- vision-guided multi-granularity text fusion을 도입해서 global and detailed text information을 fine-grained visual guidance와 integrate한다.
- Github repository: https://github.com/congvvc/InstructSeg
Motivation
여러 비슷한 task들 (RES, RVOS, ReasonSeg, ReVOS)를 묶어서 IVS를 만든다(Fig. 1) 참조.
이를 풀 수 있는 InstructSeg 모델을 제안하는데, 여기에는 두 가지 meticulous detail이 포함되어 있다:
- Object-aware Video Perceiver
- Vision-guided Multi-granularity Text Fusion
Object-aware perceiver는 temporal, object information을 reference frame에서 extract한다.
Vision-guided Multi-granularity Text Fusion은 긴 text instruction과 complex scenario를 이해할 수 있도록 한다.
Methods
주요 component는 다음과 같다:
- MLLM(CLIP 포함)
- Visual Encoder
- Object-aware Video Perceiver(OVP)
- Segmentation Decoder
- Vision-guided Multi-granularity Text Fusion(VMTF)
input은 video sequence
먼저 CLIP encoder가 모든 visual input을 global image feature로 변환한다. object-aware video perceiver는 reference frame과 text token을 가지고 fixed-length token을 generate한다.
LLM은 네 종류의 input으로 feed된다: visual tokens(image or key frame), text tokens, compressed tokens from referenced frames, mask tokens.
Object-aware Video Perceiver
VISA의 경우 off-the-shelf model에 dependency가 강하다는 문제가 있다. 여러 module들을 사용할 경우 error acculmulation이 될 수 있다.
이 문제를 tackle하기 위해, Object-aware Video Perceiver(OVP)를 제안하는데, 이는 text guide로부터 both temporal and object-specific information을 reference frame으로부터 extract한다.
→ 식을 보면 history가 들어가는 건 아니고, 각 frame마다 independent하게 들어가는듯?
이후 모든 reference tokens
여기의
Vision-guided Multi-granularity Text Fusion(VMTF)
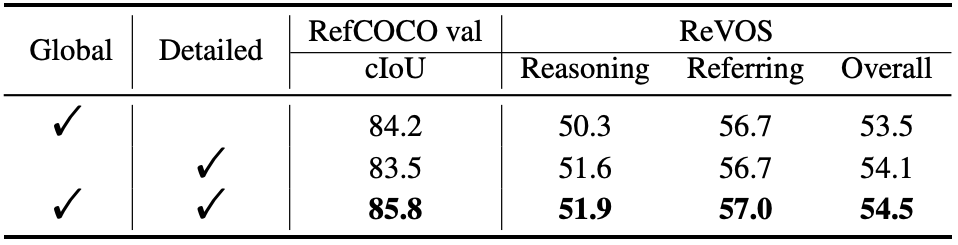
여기서 한 가지 더 지적하는 것은, 기존 method[2,3,4]들이 text token을 pool함으로써 detailed text information을 잃는다고 주장한다.
여기서는 VMTF를 만들어서 global and detailed information을 multi-granularity로 추출하여 사용함으로써 text intention에 더 잘 align되는 text embedding을 만들 수 있다고 설명한다.
구조는 Fig. 4에 제시되어 있는데, text embedding
→ 구조가 난해하네.. 왜 이렇게 했을까? 이미 LLM의 inference를 거쳐서 답이 나온 걸 또 다시 만질 필요가 있나?
Mask Decoding and Training Objectives
segmentation decoder
의 형태로 나타날 수 있다.
Training objectives
InstructSeg는 다음 loss를 가지고 end-to-end로 train된다:
Experiments
Mipha-3B(LLM), Swin-B(visual encoder), Mask2Former(segmentation decoder) 사용했다.
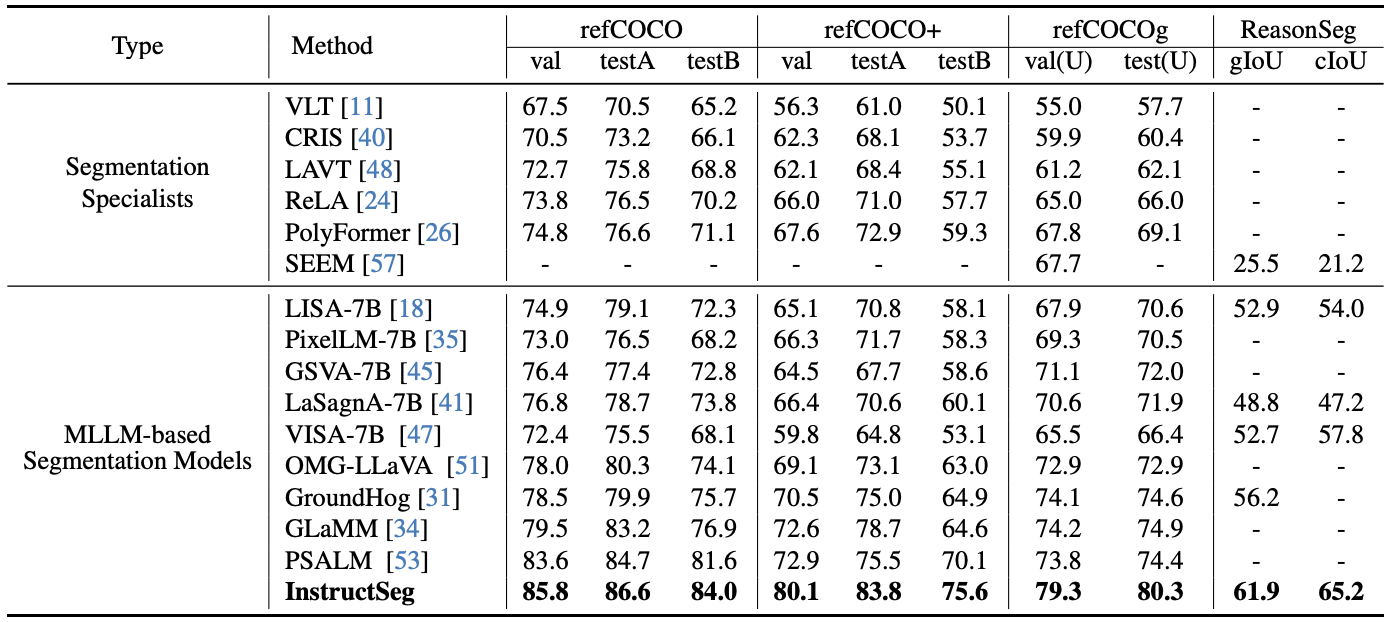
Tab. 2는 image domain의 referring과 reasoning question에 대한 결과이다. 모든 task에서 SOTA임을 확인할 수 있다.
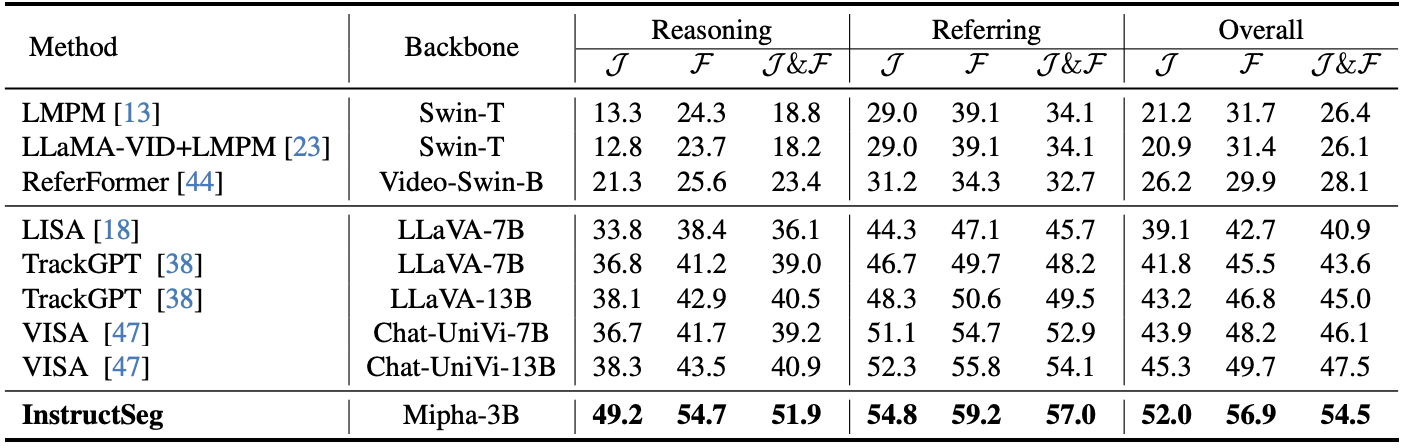
Tab. 3은 ReVOS benchmark에서의 결과인데, 꽤 큰 gap으로 앞서는 것을 볼 수 있다.
→ 근데 이건 좀 곤란한 table인게 backbone이 달라서 Mipha가 좋은건지... InstructSeg가 좋은건지..
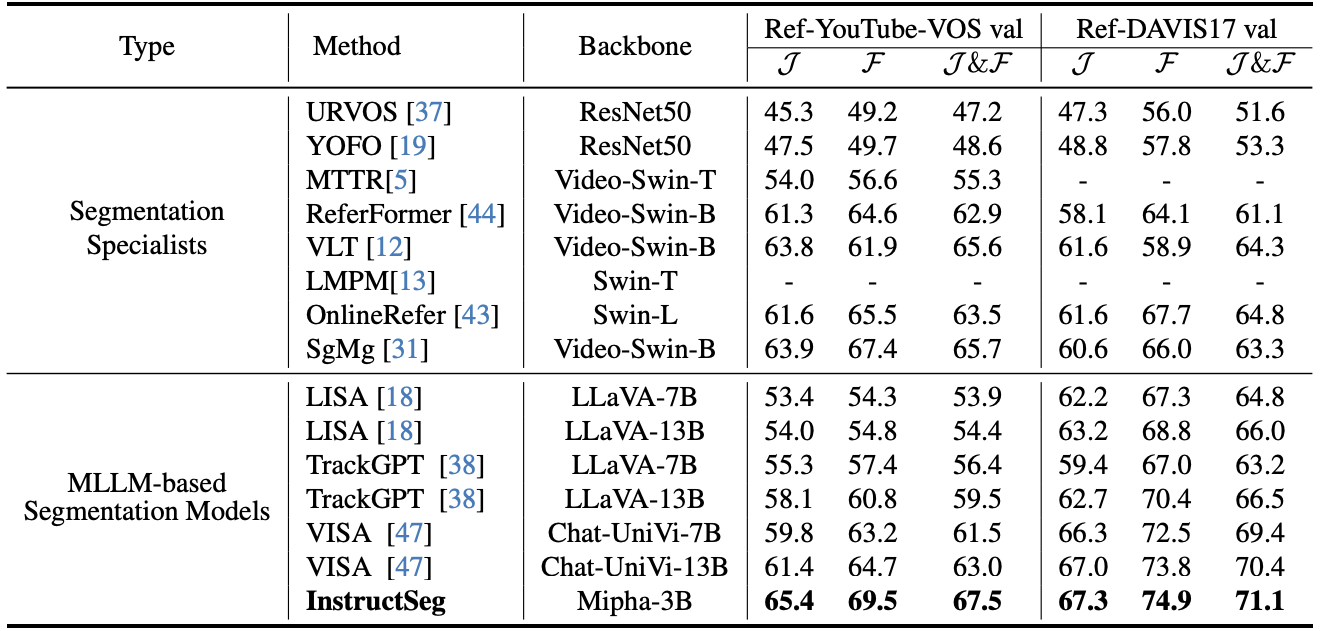
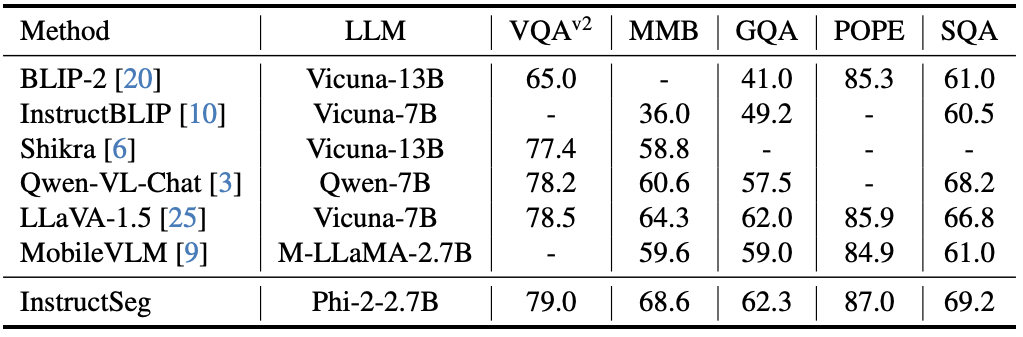
→ Fig. 5는 신기한데, text generation performance에 degradation이 없다.
Ablation Studies
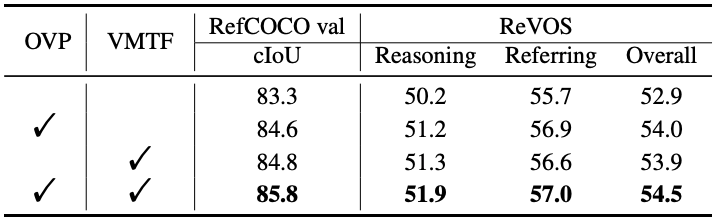
Tab. 6을 보면 별 성능 차이가 없다. 뭐지?
왜 이렇게 성능이 좋은거야? 아마 이전에 VISA에서 decoding할 때 쓰는 외부 module이 엄청 큰 bottleneck이었을 수도 있고.. 여기에 쓰는 SAM이 bottleneck이 될 수도 있을 것 같다.. 뭐가 문제였을까? 좀 더 고민해봐야 할 듯. 일단 end-to-end라는 점이 확실히 크긴 한가보다.
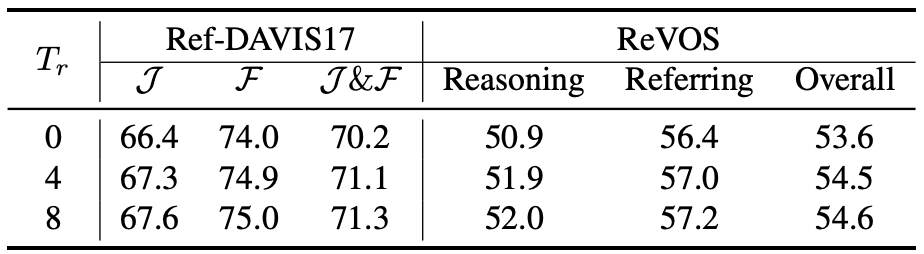
reference frame이 있다는 게 중요한 듯
Discussion
* 내가 못 본 건지 모르겠는데 keyframe하고 reference frame의 sampling 방식이 나와있지 않다. 중요한 부분인데..
-> 코드 확인해봤는데 그냥 주변 4개 frame 뽑아오는거임 (https://github.com/congvvc/InstructSeg/blob/main/instructseg/eval/seg/eval_revos.py) line 135 참조
* 성능이 엄청 좋은데 ablations를 보면 OVP하고 VMTF 덕은 아니다. 어디가 달라서 이런 결과가 나왔을까?
* detail이 많이 빠져있는 논문
References
[2] LISA
[3] VISA
[4] PixelLM
Footnotes
'DL·ML > Paper' 카테고리의 다른 글
| VideoRefer Suite (0) | 2025.01.10 |
|---|---|
| PSALM (ECCV 2024, Image Segmentation) (0) | 2025.01.10 |
| HyperSeg (arXiv preprint, seg) (0) | 2025.01.06 |
| VISA (ECCV 2024, RVOS) (0) | 2025.01.03 |
| VideoLISA (NeurIPS 2024,VOS) (1) | 2025.01.02 |