[paper review] Efficient Estimation of Word Representations in Vector Space (Word2Vec)
·
DL·ML
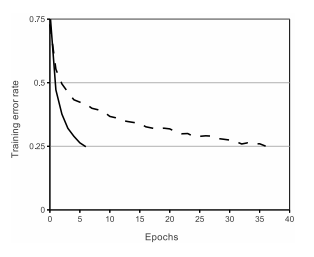
Abstract Propose two model architrectures for computing continuous word vector (CBOW, Skip-Gram) Propose two modified NNLM model using binary tree Introduce new method to measure word similarity Show that newly introduced models can be trained on very large model (reduced time complexity) Previous Works 기존에 있었던 word vector 학습 모델은 크게 두 가지로 나눌 수 있었다. 1. SVD(Singular Value Decomposition) 기반 모델 LSD(..