Abstract
- ICLR 2024 spotlight
- open-vocabulary dense prediction task
- open-vocabulary object detection, semantic segmentation, panoptic segmentation
- CLIP ViT의 문제 개선
- 추가 데이터 없이 local image region까지 aware하는 CLIPSelf 제안
- https://github.com/wusize/CLIPSelf
Motivation
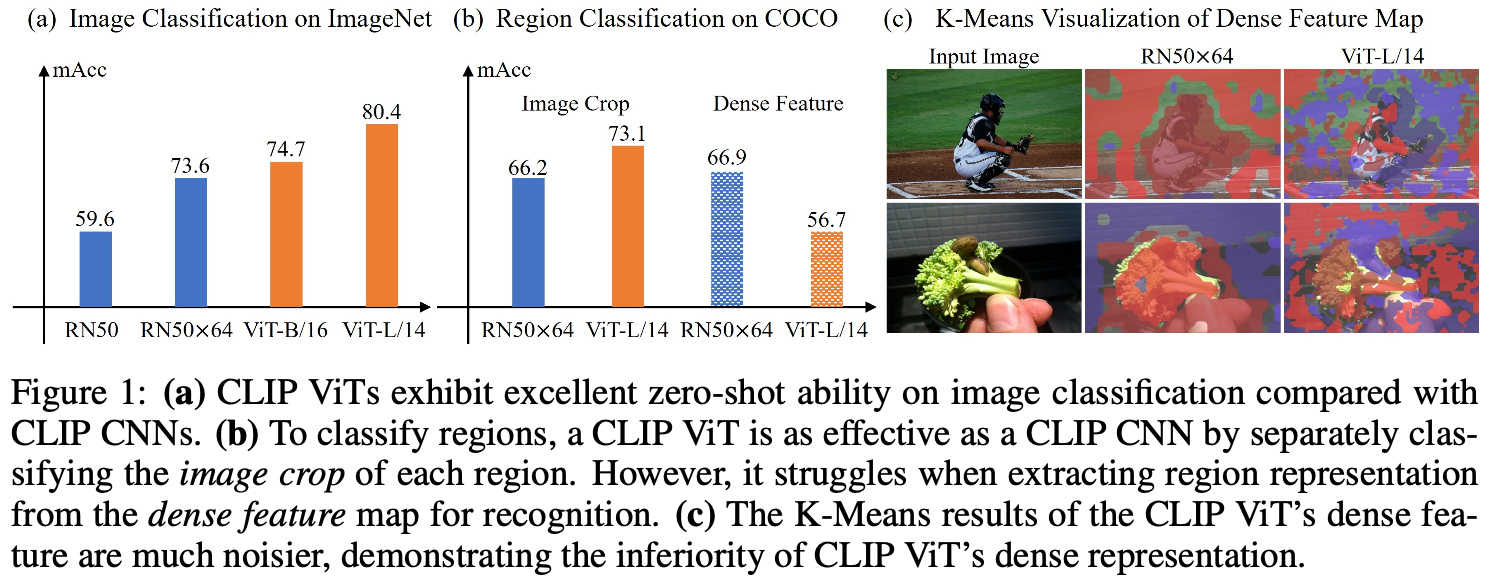
open-vocabulary approach에서는 CLIP based model을 사용한다. Fig. 1을 보면, ViT-based CLIP model이 image representation에는 강하지만, dense feature를 이용해서 region recognition에는 어려움을 겪는 것을 볼 수 있다. Fig. 1(c)에서 CLIP ViT는 K-Means visualization을 해 봤을 때, CNN based model보다 성능이 떨어진다.
CNN model과 다르게 ViT는 inductive bias가 떨어지므로 이런 일이 발생했다고 볼 수 있다. 즉, Fig. 1(c)의 결과는 global attention의 영향이라고 해석한다.
아주 재미있는 추론이고, 나도 동의한다. .
만약 ViT의 inductive bias issue에 대해 익숙하지 않다면 https://jordano-jackson.tistory.com/104 를 참조하면 좋다.
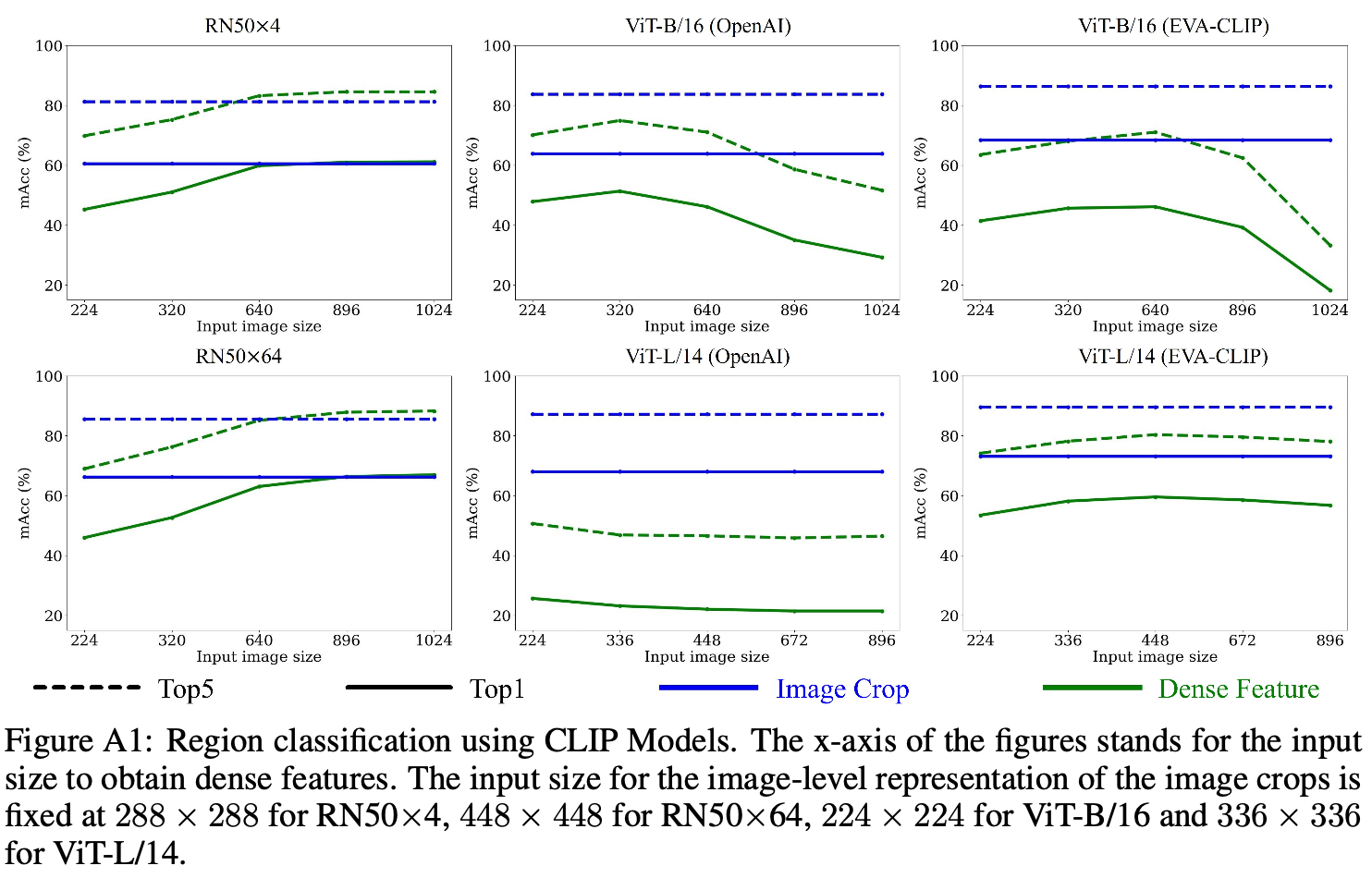

여기에 대한 intuitive한 해결방법으로 region-text pair로 CLIP ViT를 fine-tuning하는 것을 생각해 볼 수 있는데(Fig. 2(a)), 이런 annotation은 expensive하다. 여기서는 CLIPSelf를 이용해서 annotation data 없이 self-distillation으로 dense prediction을 수행한다.
fine-tuning은 CLIP-ViT의 pooled dense feature map과 해당 영역의 image crop 간의 cosine similarity를 maximize하는 방식으로 이루어진다.
Methods
Image Representation vs. Dense Representation
- CLIP's Image Representation
ViT-based CLIP의 image representation은 residual attention block을 사용한다.

여기서 $x$는 last residual attention block의 input으로 $x_0$는 class embedding이고 $\{x_i|x\in 1,2,\dots,h×w\}$는 image embedding이다. $c$는 constant이고 $Proj$는 projection layer이며 $Emb$는 layer norm과 projection layer이다.
- CLIP's Dense Representation
CLIP의 dense representation을 얻기 위해서, last residual attention block을 modify하여 사용하였다.

- Discussion and Motivation of CLIPSelf
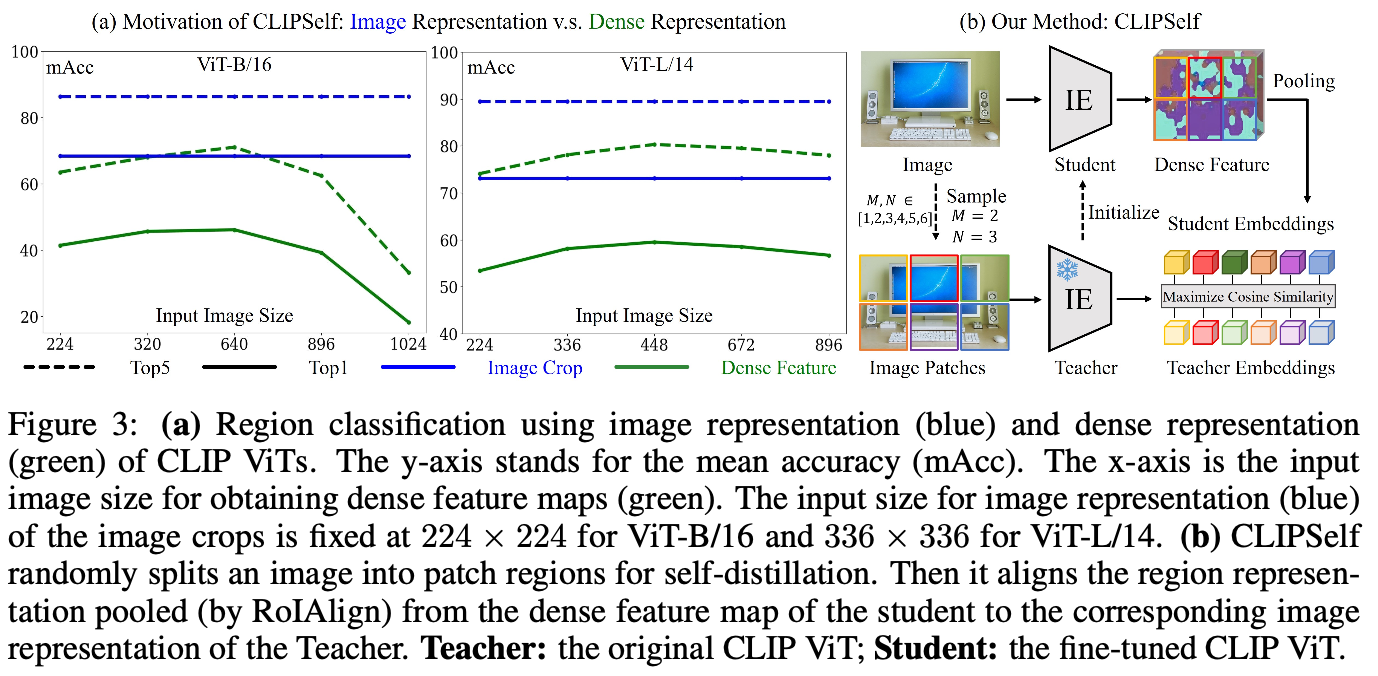
Fig. 3에서 볼 수 있듯이 classification task에서 input representation이 dense representation보다 성능이 좋았고, 이는 image size가 증가해도 달라지지 않았다. 저자들의 discussion은, 일반적으로 downstream task에서 desirable한 feature인 large image resolution이 성능 향상을 가져오지 않았다는 것은 CLIP ViT의 feature가 성능 저하의 원인이 된다는 것을 의미한다고 보았다. 따라서 dense feature map을 image representation과 align함으로 성능 향상을 기대한다.
일종의 locality를 반영할 수 있는 inductive bias의 추가라고 볼 수 있다. ViT가 global attention 때문에 vision에서 locality 반영이 안 되니, swin transformer처럼 locality를 반영할 수 있게 SSL하는 것이라고 생각된다.
CLIPSelf
self-distillation을 통해서 CLIP을 fine-tuning한다. 이때 Fig. 3(b)에서처럼 original CLIP은 Teacher가 되고, fine-tuned CLIP은 student가 된다. teacher의 weight는 freeze되고, student의 weight는 teacher와 같게 initialize된다.
- Image Patches as Regions
먼저 image를 $m×n$ patches로 나눈다. patch size가 다양해지도록 $m, n$은 $\{1,\dots,M\}$에서 randomly selected되고, $m+6$을 논문에서 사용했다. 이는 region proposal을 사용하는 것보다 background content를 인식하는 데 유리했다.
이 결과는 Tab. 2에서 확인할 수 있다.

- Self-Distillation

각 patch에 대해서 contrastive loss를 측정한다.
Results
Enhancement of Dense Representation by CLIPSelf

Application to Open-Vocabulary Tasks
open-vocabulary dense prediction task에 사용하였다.
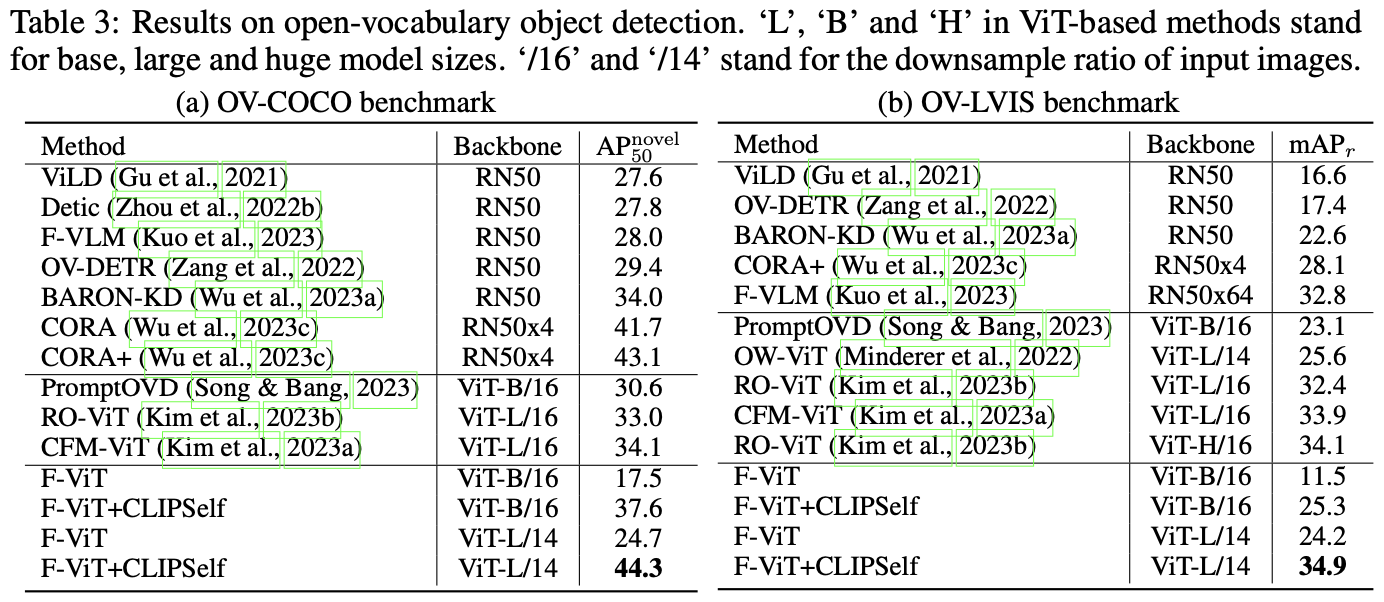
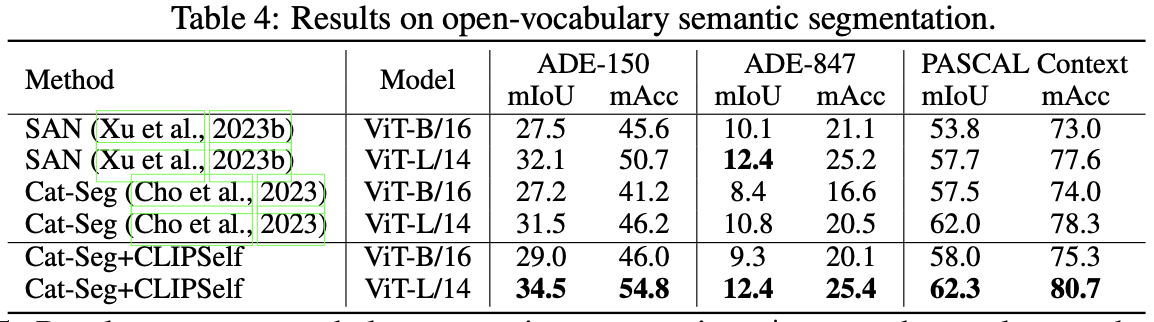
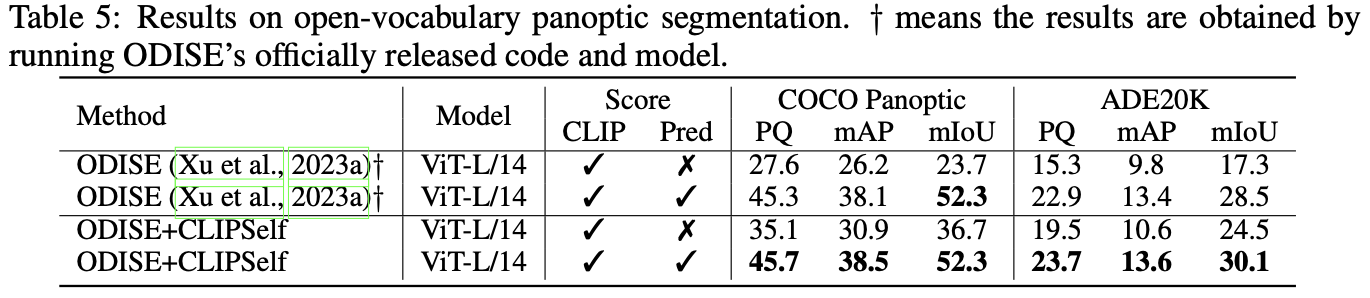
기존 SOTA module들의 CLIP ViT를 CLIPSelf로 바꿨을 경우 성능이 향상되었다.
Discussion
References
[1] Wu, S., Zhang, W., Xu, L., Jin, S., Li, X., Liu, W., & Loy, C. C. (2023). Clipself: Vision transformer distills itself for open-vocabulary dense prediction. arXiv preprint arXiv:2310.01403.
Footnotes
'DL·ML > Paper' 카테고리의 다른 글
| AGCN (CVPR 2019, action recognition) (0) | 2024.04.02 |
|---|---|
| ST-GCN (AAAI 2018, human action recognition) (0) | 2024.04.01 |
| FutureFoul (0) | 2024.03.27 |
| TesseTrack (CVPR 2021) (1) | 2024.03.27 |
| MotionBERT (ICCV 2023) (0) | 2024.03.26 |