Abstract
- soccer foul detection을 위한 CNN, RNN based approach
- bounding box position, image, estimated pose를 utilize
- 2024 Apr 4 update: https://github.com/FangJiale1999/Futurefoul_Soccer the code and dataset are now available
Motivation

soccer broadcast video로부터 foul prediction을 위한 FutureFoul system을 제안한다.
Dataset
soccer foul dataset을 구성했다.
Video Dataset
SoccerNet-v3 dataset에서 video를 가져와 사용하였다.
Selection of Foul Labels
Soccernet-v3 dataset의 4개의 "foul" tag를 가져와 사용하였고, “Ball out of play”, “Clearance”, “Shots on target”, “Shots off target”, “Offside”, and “Goal”의 non-foul tags도 포함하였다.
카메라가 많이 움직이거나 long ball movement를 필요로 하는 tag는 일부 포함되지 않았다. 집중된 foul은 주로 위험한 행동에서 비롯된 foul들로, 예컨대 "offside"는 foul로 포함하지 않았다.
또한 image에서 축구공을 찾을 수 없을 경우 해당 data를 제외하였다. 결과적으로 2,500개의 foul과 2,500개의 non-foul 데이터를 수집했다.
해당 글의 원문은 "We excluded data on fouls for which the soccer could not be found in the image." 인데, soccer를 찾을 수 없다는 표현의 의미가 모호하여 축구공을 찾을 수 없는 경우로 해석하였다.
Extraction of analysis interval
Soccernet-v3 dataset에서 "foul"로 label된 event를 filtering한 뒤, 해당 event의 정확한 시간을 record했다. 그 후 foul time으로부터 3초 이전부터 1초 후까지를 crop하여 총 4초로 구성했다.

Fig. 2에서 해당 foul event video를 확인할 수 있다. 각 video의 첫 75 frame을 training data로 활용하였다.
Extraction of bboxes with Object Tracking
ByteTrack model[2]을 활용해서 bbox를 extract했다.
foul event를 더 정확히 측정하기 위해 몇 가지 constraint를 추가했다. foul time에 넘어지는 사람의 수가 2-3명이므로 observation target을 5명으로 설정했다. 이 5명은 ball에 가장 가까운 사람으로 선택된다. 이 사람들이 계속 선택되도록 이전 time step에서 bbox 중심과 가장 가까운 사람을 track했으며 잘못된 data는 연구자들에 의해 manually check되었다.

Extraction of Estimated Pose Information
얻은 bbox data와 video data를 pretrained ResNet-50과 연결된 OCHuman model[3]로 detection했다. 5명의 people에 대해서 17개의 point를 추출했다. 이는 다음과 같다:
`[nose, left eye, right eye, left ear, right ear, left shoulder, right shoulder, left elbow, right elbow, left wrist, right wrist, left hip, and right hip]`

Extraction of bbox Image
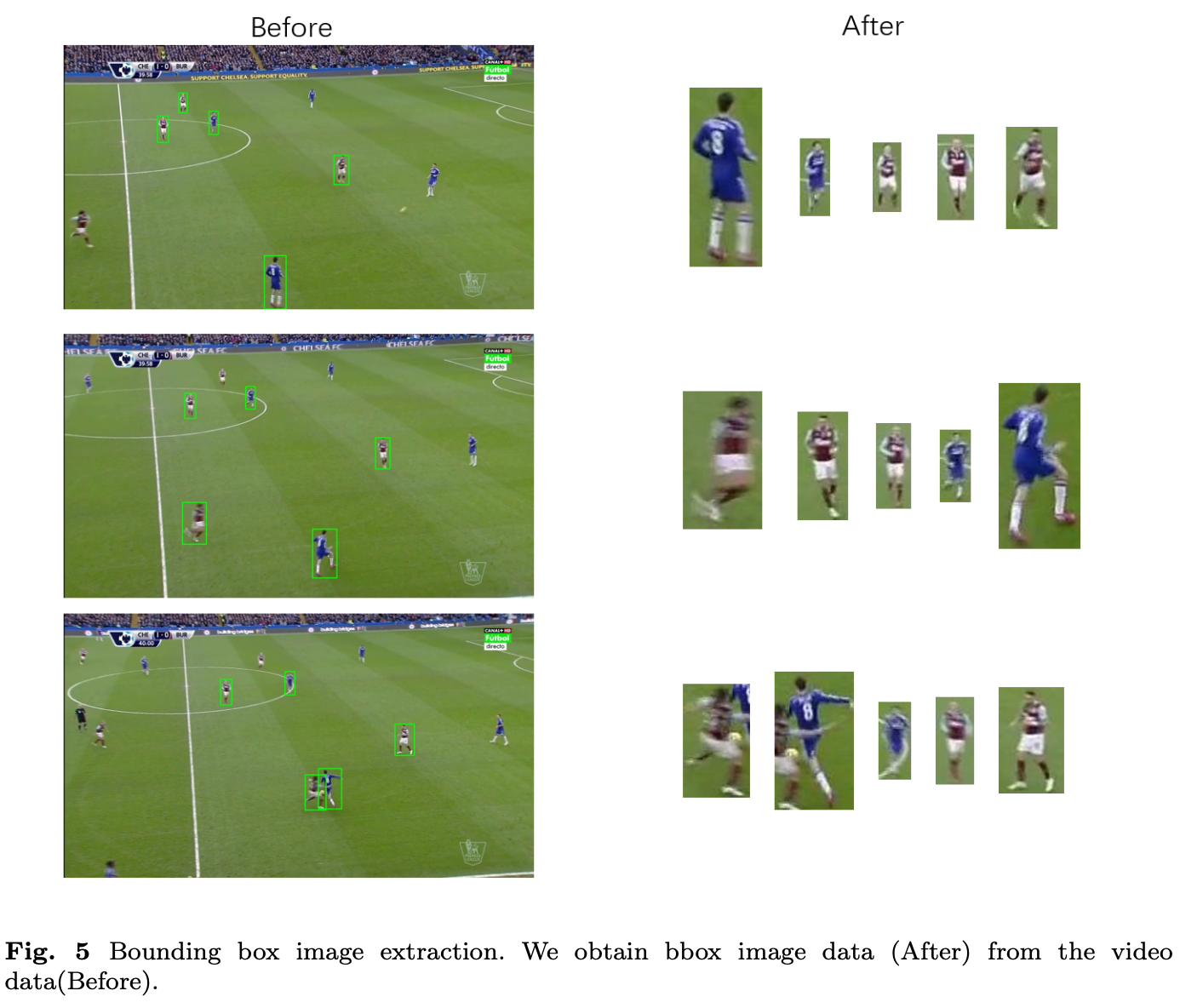
Methods

Feature Creation
data의 quality와 consistency를 ensure하기 위해서 preprocess한다. 각 video 당 4개의 frame을 subsampling(frame 1, 25, 50, 75)하고 bbox와 pose를 계산한다.
training speed를 위해서 video를 down-sampling하고 다음의 네 종류의 feature를 create하였다:
- Video: image size를 64×64로 resize했다. 이는 computational efficiency를 위한 것이다.
- Bbox: 각 player의 foot poisition을 bbox bottom center로부터 얻어 이를 model의 input으로 사용했다. soccer ball의 bbox는 사용하지 않았다.
- Pose: occlusion으로 detect되지 않는 keypoint는 0로 padding하여 사용하였다.
- BboxImg: 5명의 선수 image를 extract해서 bbox image를 model의 input으로 사용하였다.
FutureFoul
모델 구성은 Fig. 6에서 확인할 수 있다. RNN(GRU)와 CNN, MLP를 사용한다.
매우 간단한 구성이므로 특별히 설명할 만한 것은 없다.
Results
Quantitative Results


Qualitative Results



Discussion
foul을 detection하는 게 아니라 몇 개의 앞선 frame을 가지고 prediction하는 것이다.
비교할 대상은 없지만, binary classification이라는 것을 감안하면 좋은 성능이라고 보긴 어렵다. 반면 dataset 구성은 흥미롭다. 어쩌면 foul을 detection하는 데 사용할 수 있을 것으로 생각된다. 이게 없으면 직접 annotation을 해야 할 것 같은데..
dataset은 아직 공개되지 않았으나 곧 Github에 공개할 예정이라고 한다.
References
[1] Fang, J., Yeung, C., & Fujii, K. (2024). Foul prediction with estimated poses from soccer broadcast video. arXiv preprint arXiv:2402.09650.
[2] Zhang, Y., Sun, P., Jiang, Y., Yu, D., Weng, F., Yuan, Z., Luo, P., Liu, W., Wang, X.: Bytetrack: Multi-object tracking by associating every detection box. In: European Conference on Computer Vision, pp. 1–21 (2022). Springer
[3] Zhang, S.-H., Li, R., Dong, X., Rosin, P., Cai, Z., Han, X., Yang, D., Huang, H., Hu, S.-M.: Pose2seg: Detection free human instance segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 889–898 (2019)
Footnotes
'DL·ML > Paper' 카테고리의 다른 글
| ST-GCN (AAAI 2018, human action recognition) (0) | 2024.04.01 |
|---|---|
| CLIPSelf (ICLR 2024 spotlight, open-vocabulary dense prediction) (0) | 2024.03.29 |
| TesseTrack (CVPR 2021) (1) | 2024.03.27 |
| MotionBERT (ICCV 2023) (0) | 2024.03.26 |
| Grounded SAM (0) | 2024.03.25 |