Abstract
- image segmentation을 위한 foundation model을 제작
- promptable한 형태
- data engine을 활용한 large-scale supervised learning
Motivation
promptable한 segmentation foundation model을 만들기 위해서 다음 세 가지 질문을 설정한다:
- What task will enable zero-shot generalization?
- What is the corresponding model architecture?
- What data can power this task and model?

Task
promptable segmentation task를 제안한다. 이는 segmentation prompt에 따라 valid segmentation mask를 리턴하는 task이다.
이때 prompt는 text 형태일 수도 있고, 여러 개의 point와 같이 spatial한 정보일 수도 있다. 이 경우 이와 관련된 segmenation mask를 리턴하면 된다.
다만 prompt는 정확히 어떤 object를 가리키는지 ambiguous할 수 있다. (Fig. 1a 참조)
이런 형태를 고안한 이유는, 이 task에서의 pretrained algorithm이 prompt를 통해 downstream task에 zero-shot transfer를 좀 더 용이하게 할 수 있기 때문이다.
Model
model은 image encoder, prompt encoder와 이를 통해 얻은 embedding을 이용한 mask decoder로 구성되어 있는 간단한 현태이다. 논문에서는 이 모델을 Segment Anything Model(SAM)으로 명명한다. (Fig. 1b 참조)
Data Engine
segmenation mask를 만드는 일은 매우 expensive하기 때문에 데이터 양을 늘리기 위해서 자동화할 필요가 있다. 이를 위해 data sengine을 제작하여 다음의 세 단계를 통해 full automatic하게 제작하였다:
- assisted-manual
- semi-automatic
- fully automatic
1에서는 annotator와 함께 annotation한다. 2의 과정에서는 engine이 대부분을 annotate하고, 최종적으로 fully automatic하게 동작하게 된다. 이 경우 prompt는 regular grid이다.

Method
Model

전체 구조는 Fig. 4와 같다.
- Image Encoder
image encoder로는 MAE(Masked AutoEncoder)로 pretrained ViT를 사용한다.
- Prompt Encoder
prompt는 sparse(points, boxes, text) 형태와 dense(masks)형태로 들어올 수 있다. point와 box는 text prompt에 positional embedding으로 더하여 CLIP text encoder를 사용한다. dense prompt의 경우에는 convolution으로 embedding한 후 image embedding와 element-wise로 더한다.
- Mask decoder
Transformer decoder block에 dynamic mask prediction head를 붙여서 사용한다. 이 안에서 prompt와 image 간 양방향의 cross attention과 self-attention을 수행한다. 이후 MLP를 mapping하여 mask를 계산한다.

주목할 만한 점은, output token embedding이 함께 들어온다는 점이다. 이는 learnable한 것으로 ViT의 class 정보를 담고 있는 token처럼 정보를 함축해서 담는 역할을 한다.
- Resolving Ambiguity
Motivation의 Task와 Fig. 3에서 언급되었듯이, single prompt에 대한 mask는 ambiguous할 수 있다. 따라서 하나의 prompt에 대해서 3개의 mask를 generate한다.
training 과정에서는 minimum loss를 가진 mask에 대해서 backprop한다.
etc
이외 data engine에 대한 구체적인 configuration이나 data의 responsibility에 대한 분석이 있으나 생략한다.
Results
task는 zero shot ability를 측정하기 위해서 promptable segmentation task와 다른 4개의 task를 포함한 5개의 task에서 성능을 측정하였다.
즉, 다음과 같은 task들이 수행되었다:
- zero-shot single mask generation
- zero-shot edge detection
- zero-shot object proposal generation
- zero-shot instance segmentation
- zero-shot object segmentation from free-form text
Zero-shot Single Point Valid Mask Generation
gt object 의 중심에 point를 찍어 prompt로 준 뒤, confidence가 가장 높은 amsk에 대해서 mIoU를 측정한다. 이때 point에 따라 지칭하는 object가 무엇인지에 대해 ambiguity가 있으므로 mIoU를 수정하여 사용한다.

테스트를 위해서는 23개의 segmentation dataset을 사용했고, RITM[2]를 baseline으로 비교하였다.
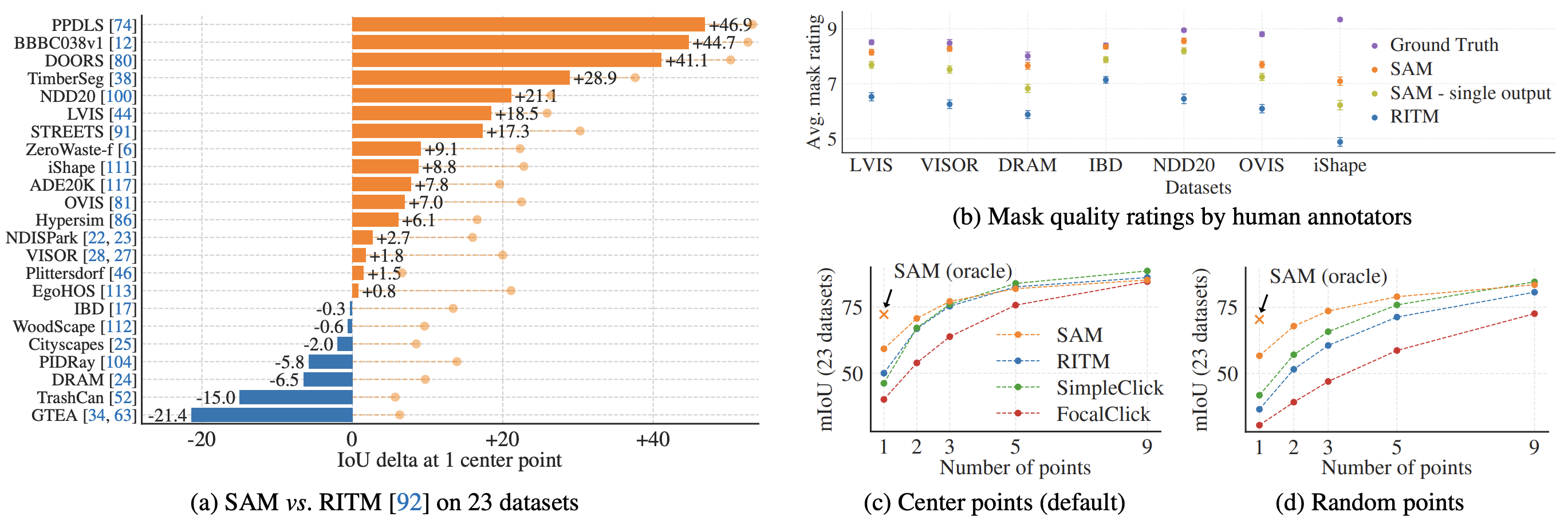
Fig. 9a는 mIoU metric에서, 9b는 human annotator의 평가를 나타낸다. 기존 baseline보다 significant하게 높은 성능을 보인다.
Qualitative Results

Fig. 10은 edge prediction downstream task에서 결과를 보여준다. 16by16 regular grid로 prompt를 넣은 다음 Sobel filtering으로 결과를 낸 것이다.

애매한 text prompt에도 잘 동작하고, 만약 실패했을 경우 point prompt가 정확도 향상에 도움을 주는 것을 볼 수 있다.
Discussion
- prompted segmenation을 위한 foundation model
- CLIP처럼 다른 architecture나 application의 구성요소로 사용 가능할 것
- data engine을 도입해서 self-supervised learning이 아닌 large-scale supervised learning으로 학습
- fine-structure를 놓치거나 small disconnected components에 대해 hallucinate하는 경우가 있음.
- 이건 demo를 조금만 돌려봐도 확인 가능하다.
References
[2] onstantin Sofiiuk, Ilya A Petrov, and Anton Konushin. Reviving iterative training with mask guidance for interactive segmentation. ICIP, 2022.
Footnotes
'DL·ML > Paper' 카테고리의 다른 글
| [task] 3D Pose Estimation (in progress) (0) | 2024.03.25 |
|---|---|
| VARS(SoccerNet) (0) | 2024.03.22 |
| HQ-SAM (0) | 2024.03.20 |
| 3D vision, PointNet (0) | 2024.03.19 |
| CAT-Seg(Cost AggregaTion approach for open-vocabulary semantic Segmentation) (0) | 2024.03.07 |