* Mon Apr 8 updated. → method, experiment detail added
Abstract
- VARS(Video Assistant Referee System)은 기존의 VAR을 automate한 것이다.
- SoccerNet-MVFoul dataset은 전문 심판이 annotate한 soccer foul의 multiple camera view dataset
Motivation

축구에 대해서는 잘 모르는데, VAR이 도입된 이후로 오심 판정률이 크게 줄었지만 그럼에도 불구하고 VAR은 담당 심판이 판정하는 것으로 여전히 오심의 여지가 있다고 한다. 따라서 constant한 decision을 만들기 위해서는 사람의 개입을 줄일 필요가 있다. 또한 사람이 개입되는 것으로 인하여 비용이 크게 증가하고 아마추어 리그나 semi-professional 리그에서는 VAR을 도입할 수 없다.
이를 fully-automatic한 Video Assistant Referee System(VARS)로 만들기 위해서 3,901 action으로 구성된 5 second 정도의 multi-view clip을 배포한다. 이는 전문 심판에 의해서 annotate되어 있다.
task는 foul type을 classify하고 player에게 주어질 sanction을 identify하기 위해서 severity를 evaluate한다.
SoccerNet-MVFouls Datasㄷt

Table 1을 보면, 이 SoccerNet-MVFouls는 sport에서 multi-view video로 나온 첫 번째 dataset이고, referee의 decision에 집중하고 있다는 특징이 있다.
video는 3,901개의 action을 2014-2017 사이의 6개의 main European 리그의 500 게임에서 추출되었으며 SoccerNet dataset에 기반한다. 또한 풍부한 경험을 가진 심판에 의해 annotate되었다.
Dataset Collection
dataset은 먼저 (i) broadcast video에서 extract되고, (ii) 같은 action의 clip을 align한 뒤, (iii) foul properties에 대해 annotate하여 만들어졌다.
- Clip extraction
500개의 full broadcast game에 대한 annotation을 가진 SoccerNet-v2 dataset을 사용하였다. 각 foul의 timestamp가 있으므로, 이를 기준으로 전 3초, 후 2초, 총 5초의 clip을 추출하였다. Fig. 2에서 확인할 수 있다.

Github repository에 4.4. 공유된 내용에 따르면 대부분의 foul은 75 frame 근처에서 발생한다.[2]
- Property annotations
다음 property가 define되었다.
- clip이 foul을 contain하는지
- foul의 class
- foul의 severity
- player가 ball을 play하는지
- play가 ball을 play하기 위해 try하는지
- player가 hand나 arm으로 ball을 touch하는지 (의도와 관계없이)
- offence인지?
- 두 player 간 contact가 있는지?
- foul이 upperbody 또는 underbody와 relate되는지?
- upper body는 arm인지 shoulder인지?
여기에 gray area를 위한 special label이 만들어졌다.
- 1번 property: "Between" → "Foul"과 "No foul" 사이에 명확하지 않을 때
- 3번 property: "Borderline No card/Yellow card"와 "Borderline Yellow card/Red card" → 각 사이에서 명확하지 않을 때
Dataset Statistics
- Number of views: 평균적으로 2.29개의 clip, 75%는 2개의 viewpoint, 20%는 second replay, 5% 정도는 3rd replay video. 4개 이상은 없음. (총 video 개수 2-4개)
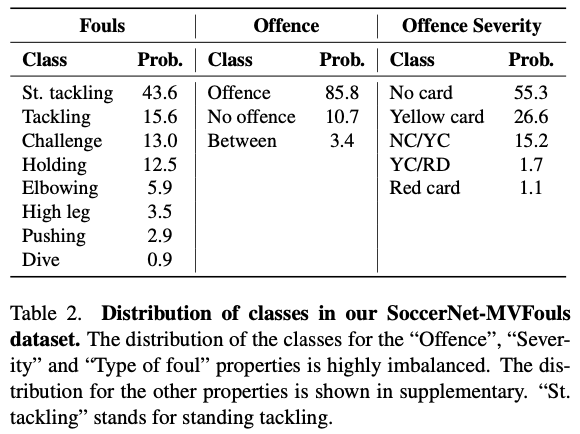
- Properties distribution: Tab. 2를 보면, skewed distribution 볼 수 있음.
- Success rate of the referees: Tab. 3에서 success rate를 확인할 수 있음.

- Severity for different foul classes: "Tackling", "High Leg", "Elbowing"은 yellow card가 잘 나왔고, "Pushing"이나 "Challege"는 카드를 잘 받지 않았다. 카드를 받았다는 것은 주로 상대방에게 공격적인 모션이 되었음을 의미한다.
Method
Task
- Fine-grained foul classification
4개의 foul class가 있다.
“Standing tackling”, “Tackling”, “High leg”, “Pushing”, “Holding”, “Elbowing’, “Challenge”, “Dive/Simulation”
각각이 정확히 무엇을 의미하는지는 추가 요망 - Offense severity classification
“No offence”, “Offence + No card”, “Offence + Yellow card”, and “Offence + Red card”
이 task에서 "Between"과 "Borderline"으로 annotate된 것은 사용하지 않았다.
VARS
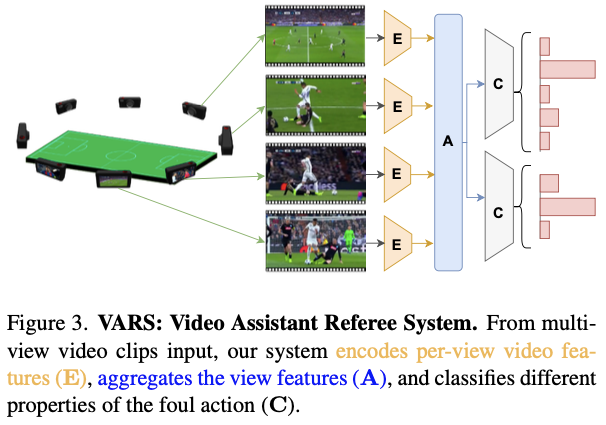
전체 architecture는 Fig. 3에서 확인할 수 있다.
여러 개의 video clip $\mathbb v = \{v_i\}^n_1$를 input으로 받아 video encoder $\mathbb E$에 feed하여 spatiotemporal feature $f_i$를 얻는다.
$$f_i = \mathbb E_{θ_E}(v_i)$$
여러 개의 video에 대한 feature를 aggregate한다. 논문에서는 max 또는 mean으로 aggregation한다고 했으나 실제 implementation에서는 attention을 사용하는 것 같다. $A$는 aggregation function이고, 이를 통해 single multi-view representation $R$을 얻는다.
$$R=A(\{f_i\}^n_{i=1})$$
이를 classification head $C_{θ_C}$에 넣어 predict한다.
$$VARS = \arg \max C_{θ_C} (R)$$
이 model에 대한 loss는 다음과 같이 정의된다:
$$ \textit{L} =\textbf{ L}(C_{θ_C} (A(\{\mathbb E_{θ_E} (v_i)\}^n_{i=1})),y)$$
$\textbf{L}$는 cross entropy이고 $y$는 groundtruth이다.
여기서 사실 foul과 offence detection은 비슷한 task이므로 두 개의 head를 붙여서 각각의 loss를 함께 optimize하였다:
$$α_{foul}L^{foul}+α_{off}L^{off}$$
implementation에서 두 $α$값은 모두 1로 설정되었다.
- Video encoder: ResNet, R(2+1)D, MViT가 사용되었다.
- Multi-view aggreagator: Mean pooling과 Max pooling이 사용되었다. Max pooling은 feature 당 max값을 취한다.
- Classification head: two dense layer with softmax activation이 사용되었다.
Experiments
Experimental Setup
- Training details: foul 전 후로 8 frame씩을 뽑아 총 16 frame, 1s의 clip을 추출했고, 각 frame은 224×398 pixel이다. video encoder는 pretrained model을 사용하였고 classification head는 scratch로 train되었다.
10 epoch 뒤에 overfit하기 시작했고, single V100으로 9시간 train되었다. - Evaluation metrics: classification accuracy와 top-2 accuracy, balanced accuacy(BA)를 제공한다.
$$\text{Balanced Accuracy (BA) } = \frac {1}{N} \sum^N_{i=1} \frac{TP_i}{P_i}$$
$N$은 number of classes이다.
Main Results
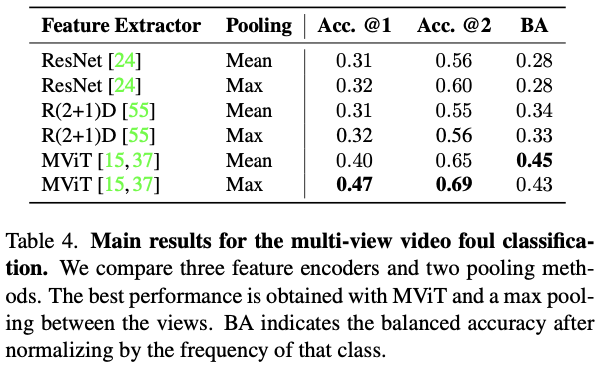
- Task 1: Fine-grained foul classification.
Tab. 4를 보면, MViT와 Max pooling based method가 성능이 좋음을 알 수 있다.
- Task 2: Offence severity classification.
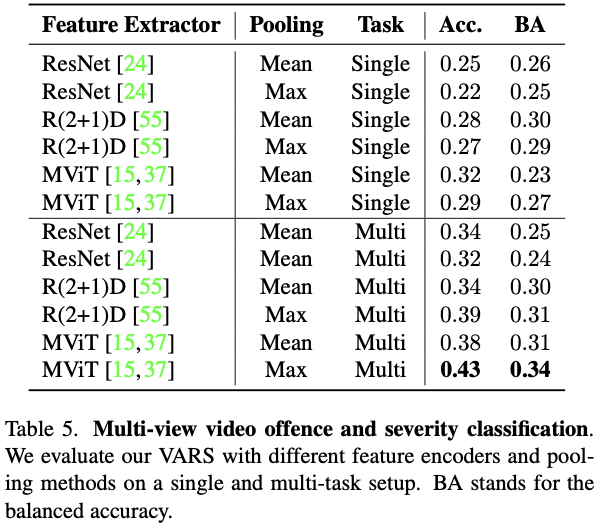
severity classification에는 어려움을 겪는다. 논문에서는 이를 두 가지 요인이 원인인 것으로 분석한다.
References
[2] https://github.com/SoccerNet/sn-mvfoul/commit/b7a35f3e36b18776cb63ddc973737b794dc3c4aa
Footnotes
'DL·ML > Paper' 카테고리의 다른 글
| Grounded SAM (0) | 2024.03.25 |
|---|---|
| [task] 3D Pose Estimation (in progress) (0) | 2024.03.25 |
| HQ-SAM (0) | 2024.03.20 |
| 3D vision, PointNet (0) | 2024.03.19 |
| SAM(Segment Anything) (0) | 2024.03.12 |