
Abstraction
- CVPR 2024 accepted
- https://ku-cvlab.github.io/CAT-Seg/
- semantic segmentation SOTA
- CLIP based architecture에 spatial aggregation과 class aggregation 더하여 성능 향상
Motivation
- open-vocabulary semantic segmentation은 image 안의 각 pixel을 text description의 class로 categorize하는 task이다.
- 최근 방법은 class-agnostic한 region proposal을 만든 뒤 CLIP encoder에 넣는 방식이었다.
- training dataset의 bias를 반영하고,
- global context를 반영하지 못한다는 문제가 있다.

따라서 본 논문에서는 pretrained CLIP의 transfer와 fine-tune을 통해 pixel-level prediction task를 가능하게 하고자 한다.
다만 fine-tune을 할 경우 CLIP의 open-vocabulary 성능이 저하됨이 알려져 있다.
CLIP에서는 cost volume이 loss computation에 사용되는데, 이것을 이용하여 image-text matching cost가 image-text pair의 relation을 explicit하게 바년할 수 있도록 한다.
Figure 2를 보면 open-vocabulary capacity가 떨어지지 않았음을 확인할 수 있다.
CAT-Seg는 세 개의 component로 구성된다.
- image와 text embedding의 cost volume
- spatial and cost aggregation을 위한 Transformer based module
- decoder
Method
Overall Architecture
Cost Compuation and Embedding
cost는 CLIP 처럼 cosine similarity로 계산한다. image encoder
이후
Cost Aggregation
spatial aggregation과 class aggregation의 두 종류 aggregation을
- Spatial aggregation
Equation 2는 Swin Transformer에서의 두 consecutive block 간 관계를 의미한다.
Swin Transformer로 shifted window에서 self-attention을 수행한다. attention은 class 별로 수행된다.
- Class aggregation
class 간의 relation을 capture하기 위해서 다른 class 간 aggregation이 수행된다.
이 경우 class 개수
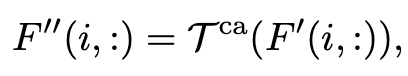
- Embedding guidance
저기에 더해서 추가적인 information을 주기 위해서 CLIP text encoder와 추가 image encoder를 사용하여 feature를 얻은 뒤 linear projection한 값을 concatenate해서 사용했다.
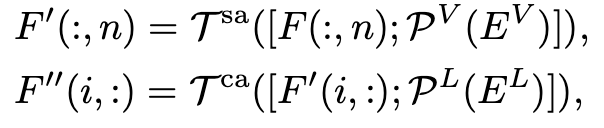
이때 CLIP image encoder를 사용하지 않았는데, 직접 utilize할 경우 성능이 저하될 수 있기 때문이다.
Upsampling Decoder
interpolation 방법인 bilinear upsampling을 하고, 이를 feature map에 concat한 뒤 convolution layer를 통과한다. 이 process를
Results
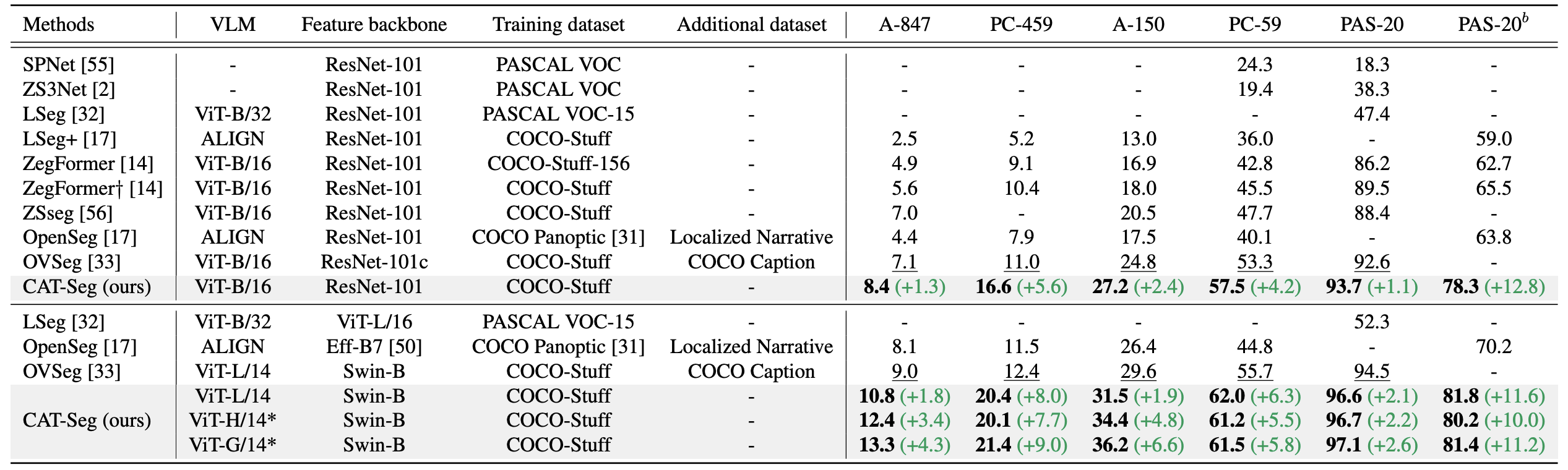
ADE20K dataset과 PASCAL VOC, PASCAL-Context dataset에 대해서 mIOU를 baseline에 대해서 측정하였다. 각 dataset 뒤의 숫자는 class 개수이다.

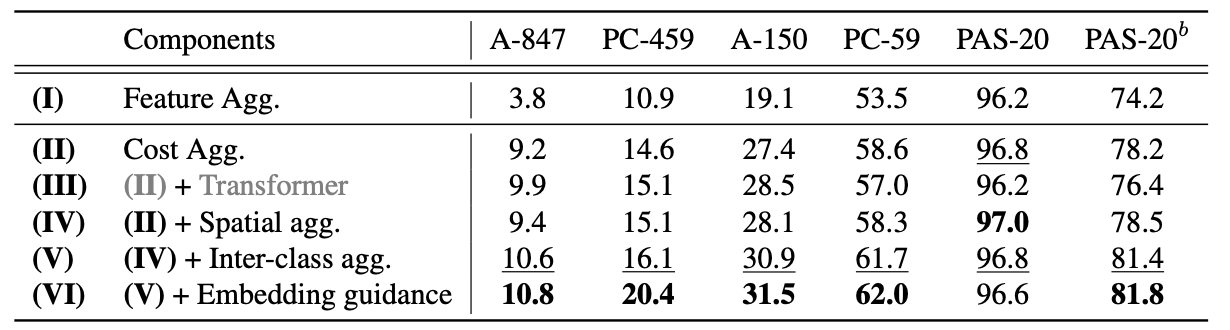
Ablation Study
References
[1] Cho, S., Shin, H., Hong, S., An, S., Lee, S., Arnab, A., ... & Kim, S. (2023). CAT-Seg: Cost Aggregation for Open-Vocabulary Semantic Segmentation. arXiv preprint arXiv:2303.11797.
Footnotes
'DL·ML > Paper' 카테고리의 다른 글
| [task] 3D Pose Estimation (in progress) (0) | 2024.03.25 |
|---|---|
| VARS(SoccerNet) (0) | 2024.03.22 |
| HQ-SAM (0) | 2024.03.20 |
| 3D vision, PointNet (0) | 2024.03.19 |
| SAM(Segment Anything) (0) | 2024.03.12 |