
Abstract
- ICCV 2023 Oral
- Video foundation model

Motivation
기존의 VFM에 대한 연구는 video data의 computational cost로 인해 주로 IFM 기반으로 이루어졌지만, image와 video는 domain이 다르다. 주로 motion에 대한 understanding이 lack되어 있는 특성이 있고 scene 위주로 집중한다. 또한 IFM은 temporal한 상황 인식이 없고 spatial한 인식이 구성된다. 이런 문제는 책을 펴고 덮는 motion에 대한 인식을 어렵게 만든다(See Fig. 2).
여기서는 temporal-sensitive VFM을 efficient하게 training하기 위해서 UMT(UnMasked Teacher)를 도입한다. 이는 기존 IFM에 dependent하지 않고 ViT를 scratch부터 train한 것이다. 이때 semantic 정보가 적은 video token은 mask하고 unmasked token만 teacher와 align한다.
various video task를 다루기 위해 progressive pre-training framework를 사용했다(See Fig. 2). Stage 1에서는 masked video data를 사용해서 masked video model에 사용해 video-only task를 풀 수 있도록 했다. Stage 2에서는 public vision-language data를 가져와 multimodal로 train했다. 이로 얻은 여러 task에서의 결과는 Fig. 1에서 확인할 수 있다.
Methods
Unmasked Teacher
IFM을 VFM을 train하는 teacher network로 사용헀다. Video-MAE에서 영감을 받아 mask modeling을 video를 train하는데 사용하였다. 다만, extra decoder를 없애고 unmasked token을 teacher과 align하는 데에만 사용했다는 점이 차이점이다.
- Architecture
CLIP-ViT를 teacher로 사용헀다. backbone으로는 vanilla ViT를 사용했고, class token은 제외했다. 여기에 spatiotemporal attention을 추가하여 unmasked token temporal하게도 interact하도록 했다. temporal downsampling하지 않았으므로 token은 frame에 align될 수 있다.
- Masking
VideoMAE의 세팅을 따라서 80%를 masking했다. 만약 80%로 random masking할 경우 대부분 background만 남아 올바르게 distill할 수 없으므로 semantic masking을 사용했다.
semantic token의 importance를 계산하기 위해서 해당 frame의 CLIP-ViT의 self-attention 값을 사용했다. 이때 class token
또한 raw video에서 frame을 sparsely sample하므로 action 간 temporal 거리가 길어 model이 long-term spatiotemporal relationship을 추론하도록 하였다.
- Target
teacher model은
Progressive Pre-training
video understanding을 위해서는 video-language task에 대해서 train하는 것이 중요하지만 scratch로 학습하는 것은 너무 expensive하다. 따라서 effective한 training-efficient framework를 사용했다.
- Pretraining pipeline
Stage 1에서는 ViT를 unmasked teacher를 distill하는 방식으로 scratch부터 training했다. 이를 통해서 video-only task를 수행할 수 있게 된다.
Stage 2에서는 pretrained ViT를 pretrained text encoder와 cross-modal decoder를 붙였다. 그 뒤 large-scale vision text pair에 대해서 multimodality training하여 video-language task를 수행할 수 있도록 했다. 이때 language model은 일반적으로 성능이 좋은 모델이 잘 알려져 있으므로 scale up하기가 용이하다.
- Pretraining objectives
모든 stage에서 unmasked token alignment(UTA)를 수행하였다. Stage 2에서는 VTC(Video-Text Contrastive) learning을 수행하였는데, 이는 unmaked video pooling 결과와 text embedding 간 align을 하는 objective이다. VTM(Video-Text Matching)으로 cross modal fusion을 enhance했다. MLM(Masked Language Modeling)은 cross modality decoder를 사용해서 unmasked video token과 text token을 이용해서 masked word를 predict하는 task로 진행되었다.
Experiments
- Why does UMT work?
Tab. 1에서 S는 spatial attention만, ST는 spatiotemporal attention을 사용하는 모델을 보여준다. 이때 ST를 사용하는 경우 가장 performance가 좋았는데, 이는 unmasked token 간 interaction이 실제로 이루어짐을 보여준다. 또한 masked model도 중요한 역할이었음을 볼 수 있다. 또한 video domain에서 post-training 없이 CLIP-ST를 바로 사용하는 것은 suboptimal한 결과를 내는 것을 볼 수 있다.
이외의 결과는 다음과 같다. 자세한 것은 해당 paper를 참조하면 좋다.
Single Modality Tasks
Multi-Modality Tasks
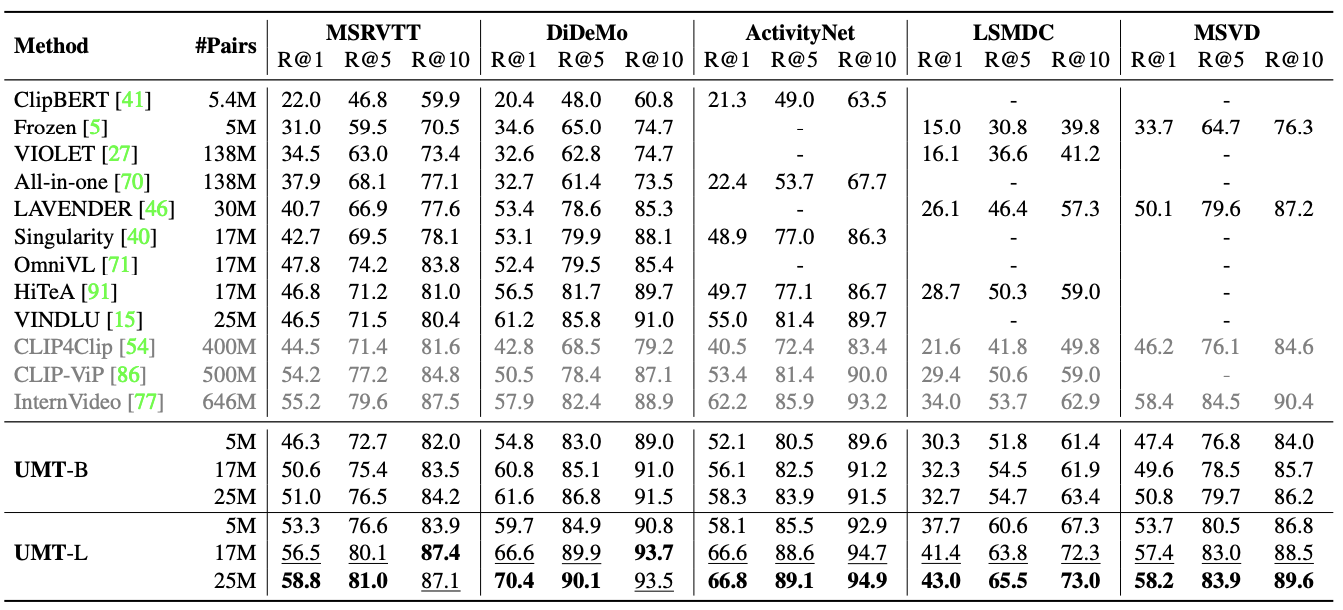
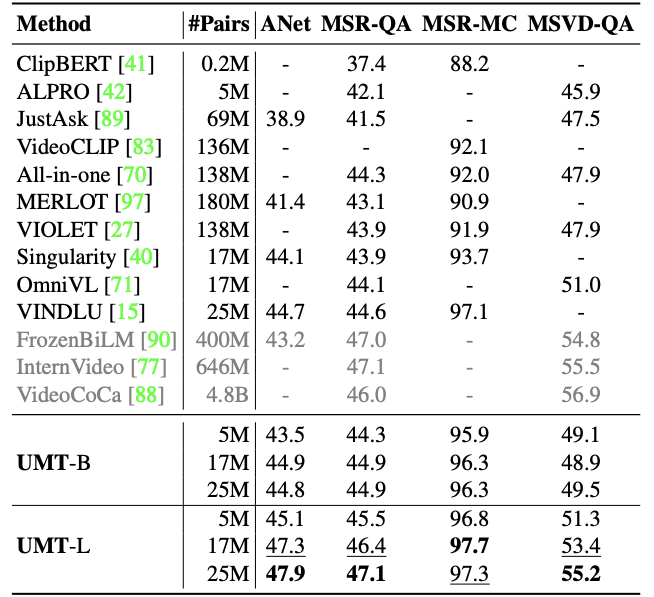
Discussion
decoder를 사용하지 않고 IFM의 knowledge를 mask를 이용해서 distillation하고 two-stage로 training하며 cross-modality에 대해서도 training 한 video foundation model이다.
References
Footnotes
'DL·ML > Paper' 카테고리의 다른 글
| DDPM (NeurIPS 2020, Diffusion) (1) | 2024.06.11 |
|---|---|
| VideoChat2 (CVPR 2024, MLLM) (0) | 2024.05.28 |
| MViT v1 (ICCV 2021, Video Recognition) (0) | 2024.05.18 |
| U-Net (0) | 2024.04.15 |
| GLA-GCN(ICCV 2023, 3D HPE) (0) | 2024.04.03 |