https://icml.cc/virtual/2024/poster/33745
ICML Poster NExT-Chat: An LMM for Chat, Detection and Segmentation
Abstract: The development of large language models (LLMs) has greatly advanced the field of multimodal understanding, leading to the emergence of large multimodal models (LMMs). In order to enhance visual comprehension, recent studies have equipped LMMs wi
icml.cc
Abstract
- pix2seq에 영감을 받은 pix2emb 제안
- pix2emb를 이용한 MLLM인 NExT-Chat 제안
- visual grounding, region captioning, grounded reasoning할 수 있음
Motivation
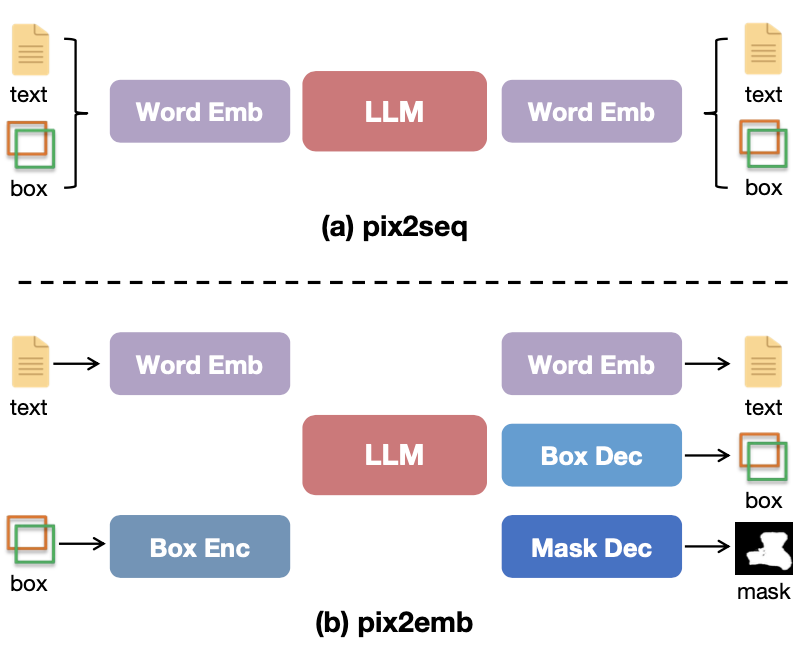
location information을 embedding으로 정의하는 방법을 사용한다.
이를 위해 <trigger> token을 정의하는데, 이 token의 hidden state가 OD와 Seg에 사용될 수 있는 것이다. 다만 이렇게 했을 경우 captioning loss로 indirect하게만 train될 수 있는 점을 지적해서, cycle consistency loss를 정의한다.
이 방법으로 multi-stage training하여 만든 MLLM인 NExT-Chat은 LISA보다 좋은 성능을 보였다.
Methods
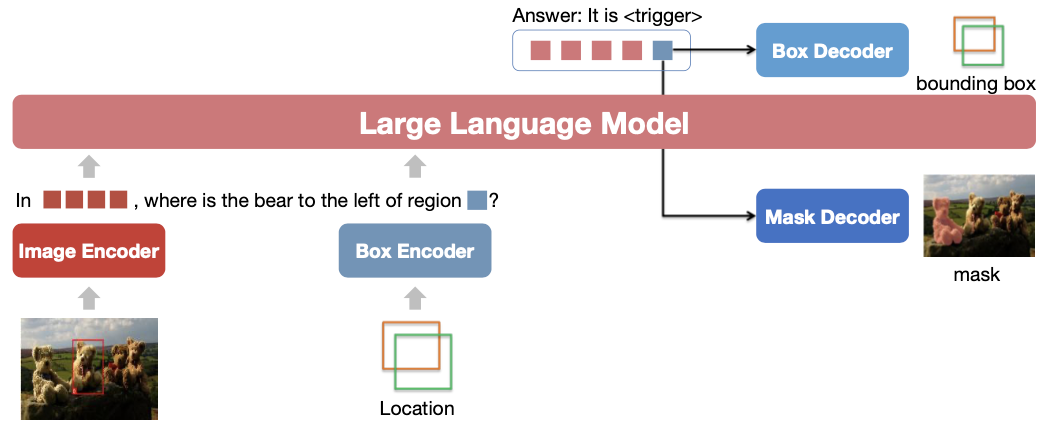
image encoder로 CLIP ViT를 사용한다. LLM으로는 Vicuna-1.5를 사용한다.
Pix2Emb Method
Detection
trigger embedding은 2-layer MLP box decoder를 거쳐 coordinate regression에 사용된다. box location output에 대해서 regression loss는 다음과 같이 계산된다:
$$\mathcal{L}_{det} = α_d\mathcal{L}_1(b,b_{gt})+β_d \text{GIoU}(b,b_{gt})$$
Segmentation
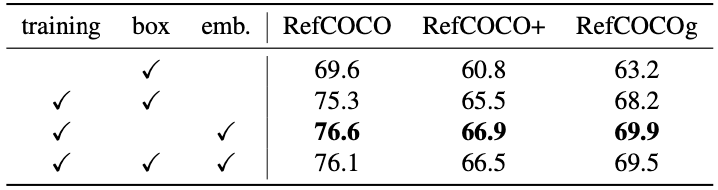
SAM decoder를 사용했다. detected bounding box는 SAM의 prompt로 사용될 수 있지만, hidden state를 직접 사용하는 것이 더 좋은 performance를 얻었다(Tab. 6 참조). 나머지 setting은 LISA를 따랐다.
$$ \mathcal{L}_{seg} = α_s\text{BCE}(m,m_{gt}) + β_sD(m,m_{gt})$$
loss는 BCE와 DICE loss를 사용했다.
Location Input
input으로도 bbox가 들어가는데 2-layer MLP로 encode했다. mask를 그리는 것은 불편해서 mask encoder는 추가하지 않았다.


loss는 eq. 4와 같이 정의도는데, $\mathcal{F}$는 box decoder, $\mathcal{G}$는 location encoder이다. input bbox를 encoder-decoder 거친 후에 L1 loss, predicted embedding $t$가 decoder-encoder를 거친 후의 embedding L2 distance를 측정한다.
Training Process
3-stage로 train했다.
Stage-1에서는 simple conversion과 bbox에 대해, stage-2에서는 conversation ability를 개선, stage-3에서는 output format을 segmentation mask로 바꾸었다.
Experiments

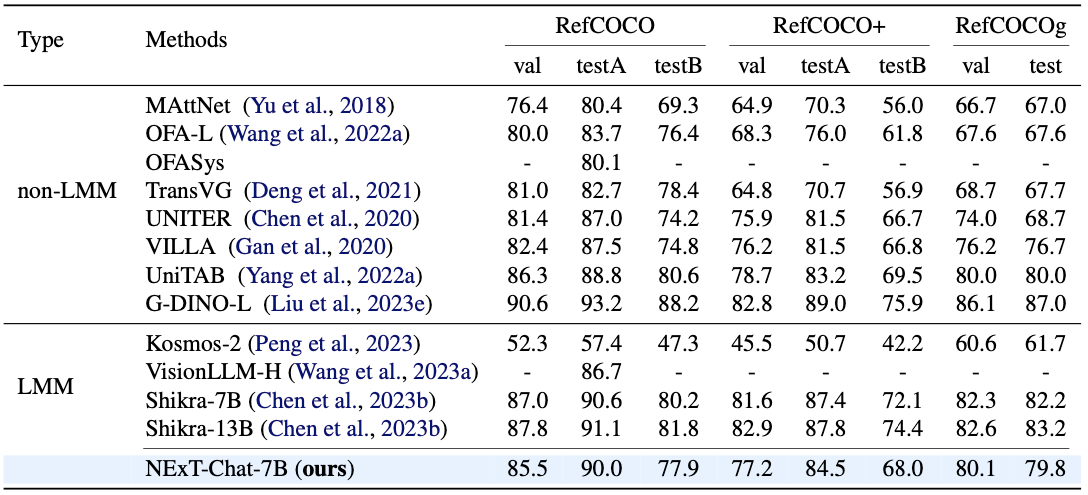
task는 visual grounding, grounded captioning, region captioning, reasoning에 대해서 측정되었다.



Discussion

* 상당히 나이스한아이디어
* 특히 box encoder train하는방법은 눈여겨볼만함
* segmentation과 동시에 할 수 있도록 하나의 token으로 만든거는 implementation 확인해보면좋을듯
References
Footnotes
'DL·ML > Paper' 카테고리의 다른 글
| Video Token Merging(VTM) (NeurIPS 2024, long video) (1) | 2025.01.24 |
|---|---|
| TemporalVQA (0) | 2025.01.22 |
| STVG (VidSTG, CVPR 2020) (0) | 2025.01.21 |
| LongVU (Long Video Understanding) (0) | 2025.01.20 |
| LaSagnA (Segmentation) (0) | 2025.01.14 |