https://arxiv.org/abs/2404.08506
LaSagnA: Language-based Segmentation Assistant for Complex Queries
Recent advancements have empowered Large Language Models for Vision (vLLMs) to generate detailed perceptual outcomes, including bounding boxes and masks. Nonetheless, there are two constraints that restrict the further application of these vLLMs: the incap
arxiv.org
Abstract
- MLLM을 image domain의 mask, bbox generation에 활용하는 경우
- multiple target handling이 안 되는 경우
- query object의 absence를 identify하지 못하는 경우
- complex query에 대한 sequence format을 define
- 이를 풀 수 있는 strategy 제안
Motivation

기존의 MLLM을 사용하는 데에 문제가 되는 두 drawback을 지적한다:
1. the ineptitude to handle multiple targets in a single query
2. the incapacity to identify the query objects/categories actually exist in the image
기존 MLLM(LISA)는 한 번에 하나의 object만 recognize할 수 있다. 따라서 여러 object를 얻기 위해서는 complex post-processing이 요구된다. 또한, query object가 image 내에 존재함을 assume해서, false prediction을 만들기 취약하다는 단점이 있다.

이외에도 세 가지 문제를 더 지적하는데, 이는 Fig. 2에서 나타난다. 이 세 문제를 해결하기 위해 다음 방법들을 제안한다:
(a) random classes list to deal with length inputs
(b) sequence augmentation to handle incomplete predictions
(c) maintaining category order alignment with the query to resolve the issue of inconsistent responses
→ 언제 발생하는 문제라는 건지? 실제로 어떤 모델에서 언제 발생하는 건지 안 써 있다. 이것만 봐서는 왜 저런 문제들이 발생했고, 얼마나 자주 발생하는 중요한 문제인지 잘 모르겠다.
여기서 제안하는 모델은 LLM-based Segmentation Assistant for Complex Queries (LaSagnA)으로 위의 문제들을 해결한 방법이다.
→ 이름이 억지다.
Methods

LaSagnA는 LISA를 base로 제작되었다. vision encoder와 decoder는 SAM을 따른다.
Learning with Complex Sequence
complex query는 multiple target과 absent category를 포함하고 있는 query이다. 기존 training query에 non-existent category를 추가해서 사용하며, format은 다음과 같다:

이 방식으로 semantic segmentation task를 train했을 때, 세 종류의 문제가 발생했다고 설명한다.
1) Incomplete predictions
종종 일부 class를 predict하지 않는데, 이는 training data에 존재하지 않는 class들로 인한 uncertainty 때문으로 보았다.
2) Lengthy input sequences
class 개수가 많은 경우 token 개수가 너무 많아진다는 문제가 있다.
3) Inconsistent category names
open-set segmentation scenario에서 specified된 category name이 아닌 training data의 category name을 활용하였다.
Training Recipes on Complex Queries
1)의 문제를 해결하기 위해 negative class들도 답변에 추가하였다. 모든 class에 대해 mention하고, negative prediction은 <NEG> token으로 답변하게 하였다.
2) class list에서 random sampling했다. 이를 통해 training set을 dynamic list로 다루게 되었다. → 일종의 bootstrapping
3) training dataset에 query와 answer가 더 similar하게 만들었다.
→ 사소한 문제들이고 해결 방법도 trivial한데 왜 이렇게 거창하게 다뤘는지 모르겠다.
Experiments



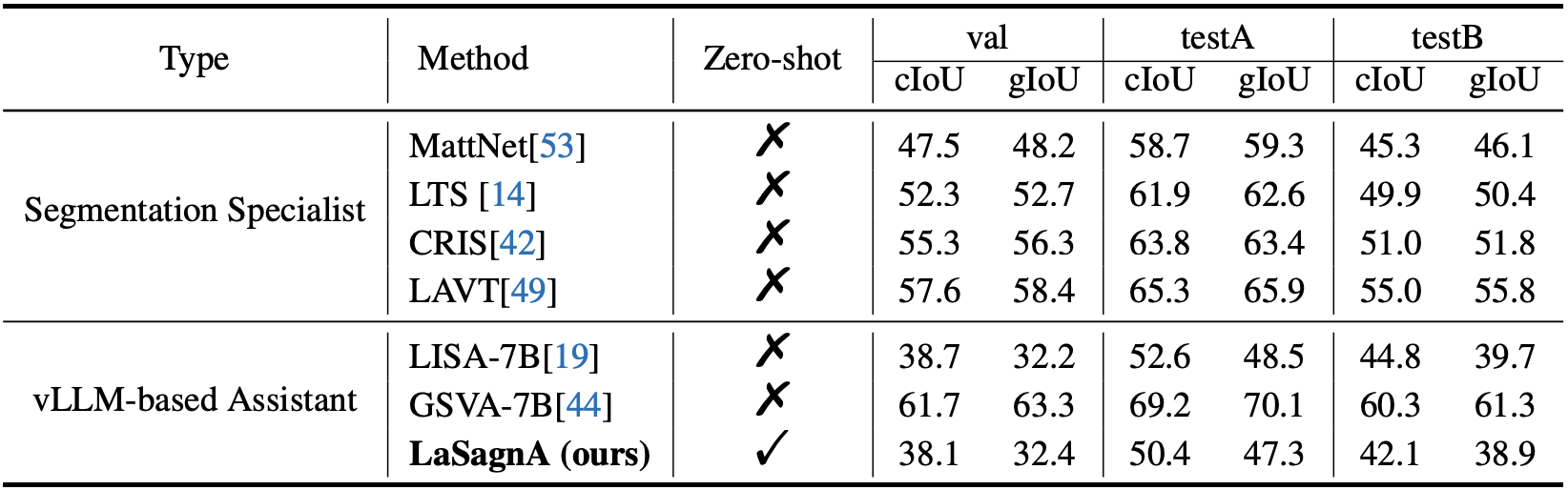


Results
Discussion
* 새로운 능력이 생기기는 했는데, 성능이 너무 별로다. 어느 정도는 기존 expert model을 따라가야지. . .
* 그렇다고 LISA에 비해 RIOS나 ReasonIOS에서 훨씬 좋은 것도 아니다.
* method라고 하는 것도 LISA에 새로운 input을 넣었다 말고 특별히 볼 것이 없다.
* problem definition은 좋았는데 . . .
References
Footnotes
'DL·ML > Paper' 카테고리의 다른 글
| STVG (VidSTG, CVPR 2020) (0) | 2025.01.21 |
|---|---|
| LongVU (Long Video Understanding) (0) | 2025.01.20 |
| VideoRefer Suite (0) | 2025.01.10 |
| PSALM (ECCV 2024, Image Segmentation) (0) | 2025.01.10 |
| InstructSeg (arXiv preprint) (0) | 2025.01.07 |