End-to-End Object Detection with Transformers
We present a new method that views object detection as a direct set prediction problem. Our approach streamlines the detection pipeline, effectively removing the need for many hand-designed components like a non-maximum suppression procedure or anchor gene
arxiv.org
End-to-End Object Detection with Transformers
Abstract
- object detection을 direct set prediction problem으로 해석
- NMS나 anchor 등의 hand-designed component를 제거
Motivation
- 기존까지는 object detection task를 여러 step으로 해결함.
- end-to-end 형태의 architecture를 접근방식을 제안한다.
- iDeA; 사실 end-to-end의 object detection 자체는 새로운 건 아님. YOLO도 있었으니까.. 근데 Transformer를 적용한 방식에 대한 이야기일듯

- object detection을 direct set prediction problem으로 개선함; 이 architecture를 DEtection TRransformer (DETR)으로 명명
- 일반적인 CNN과 transformer로 해결 가능; NMS나 anchor 등 필요 없음
- Figure 1처럼 모든 object를 한 번에 predict하고 bipartite matching함
- 결과에서는 Faster R-CNN baseline에 비교하여 COCO dataset으로 비교
- 큰 object에 대해서는 잘 수행하나 작은 object에서 어려움을 겪는 문제
Method
핵심 부분인 set prediction loss와 archiecture에 대해서 다룬다.
Object Detection Set Prediction Loss
detection 과정은 다음과 같다.
- image 안에 $N$개의 object $y$를 생성한다. 이 때 $N$은 일반적인 object의 개수보다 많다. 만약 gt object 개수가 부족할 경우∅(no object) padding을 붙여 $N$개를 만든다. 각각의 $y$는 $y_i=(c_i,b_i)$이다. $c_i$는 class label, $b_i\in[0,1]^4$는 gt box vector이다.
- N개의 prediction $\hat y = \{ \hat y_i \}^N_{i=1}$를 만든다.
- loss가 가장 작게 나오는 permutation $\sigma \in \Sigma_N$을 Hungarian algorithm으로 찾아서 equation 1의 matching cost가 가장 작은 index의 permutation $\sigma$를 찾는다.

이를 통해 얻은 index로 loss를 다음과 같이 계산한다.
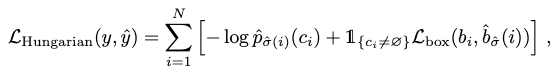
여기서 뒤쪽의 box loss는 L1 loss와 IoU loss를 linear combination해서 사용한다.

L1 loss만 쓰는 건 scale에 따라 값이 달라진다는 문제가 있어서, 단독으로 사용하긴 어렵고, IoU loss를 함께 사용한다. lambda 값은 hyperparameter 값이다.
DETR Archietecture

전체 architecture는 세 부분으로 구성되어 있다. CNN base의 backbone network, tranformer, FFN prediction head이다.
- 먼저 image를 받아서 activation map을 만든다.
- transformer에 넣을 sequential input을 만들기 위해 $d \times H \times W$ map을 $d\times HW$로 linearize한다.
iDeA; DETR이 '20. 5.에 나왔고 ViT가 '20.10.에 나왔으니 시기상 차이는 있지만, image를 patch화하면 map을 다르게 넣거나 backbone을 ViT로 써서 더 간단하게 할 수 있을 듯. 그런 연구가 있는지는 아직 안 찾아봤다
- transformer encoder에 특이한 점은 없고, decoder가 특이함. autoregressive하게 output을 만들지 않고 parallel하게 모든 output을 한 번에 계산
- transformer의 encoder와 decoder는 permutation invariant하므로 positional encoding을 더해주어야 함.
- encoder는 기존 방식대로 넣지만 decoder는 learnable한 positional embedding을 object query라는 이름으로 넣어준다.
- 이후 3 layer FFN에 넣어서 class label과 box coordinate 계산
- Auxiliary decoding loss를 training 과정에 decoder에 추가하는 것이 성능 향상에 도움이 되었음
Results
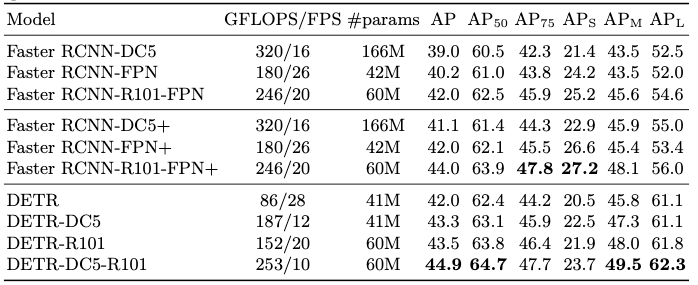
Table 1은 COCO dataset에 대한 baseline과의 비교 결과
Ablations

Figure 3은 last encoder의 self-attention map으로 각 object을 포착하고 있음을 확인할 수 있음
References
[1] Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., & Zagoruyko, S. (2020, August). End-to-end object detection with transformers. In European conference on computer vision (pp. 213-229). Cham: Springer International Publishing.
'DL·ML' 카테고리의 다른 글
| Grounding DINO architecture (0) | 2024.02.27 |
|---|---|
| [Object Detection] DINO (0) | 2024.02.21 |
| [ZSD] GLIP (2) | 2024.02.06 |
| [Paper Review] Emerging Properties in Self-Supervised Vision Transformers (1) | 2024.02.06 |
| LLaMa2(GPT3) 사용기와 에러 정리 (1) | 2023.11.30 |